

With platforms like Tray, business technologists are able to take advantage of their vendor’s open platforms to stand up and maintain critical integrations faster than ever before.
To that end, today I want to walk you through how we stood up a custom Salesforce Sync with Iterable in less than 2 weeks and how you can steal the work we did and do the same with your CRM.
How we got here
Before diving into the solution, a little context is in order.
For the last few years, we’ve been a Marketo shop - but nobody was ever really happy about that. While they may have at one time been a cutting edge marketing automation platform, in my opinion, their progress has essentially ground to a halt. The usability of the platform hasn’t improved for years, it’s slow, their approach to data is outdated, and the cherry on top? They’ll charge you an arm and a leg for the privilege of owning this pricey monolith - god forbid you grow your database size — look out $$$$! Honestly this is the case with pretty much every major MAP on the market today.
There are better solutions, focused on more narrow aspects of the classic MAP jobs to be done:
Marketing Automation Platform jobs-to-be-done
1. Marketing Asset Management: Host various marketing assets like images, PDFs, etc… We moved this to Contentful.
- Lead Lifecycle Management: Capture, validate, enrich, route, and maintain status of your leads place in the funnel. We use our own platform for this.
3. Multi-Channel Database Marketing: Database segmentation, multi-step personalized journies via multi-medium channels. We moved this to Iterable.
We migrated our database marketing needs to Iterable for the following reasons:
- Usability: It’s far easier for campaign teams to create email templates and journeys/campaigns
- Better approach to data: Iterable offer’s a highly flexible data model, easily handling both stateful and event driven data to personalize communications throughout the customer journey
- Customer focus: When you get into an engagement with Iterable, you can tell they’re a customer-first company. From the sales process, to what’s on their roadmap, or how you’re treated in onboarding - our business clearly matters to them
- Value/ROI: Their pricing model is not only an order of magnitude less expensive then Marketo, but it also scales FAR more cost effectively
The catch?
Iterable doesn’t offer a native Salesforce integration. Dangit! For many RevOps teams, this would place them dead in the water — not when you have platform like Tray though.
* A brief note the Iterable team does offer a 3rd party managed service for Salesforce syncing, but we wanted control over the sync so we could monitor the health of the sync and quickly make changes like mapping new fields or adding new source objects.
CRM Sync Solution Overview
With this solution, we’ll be syncing Salesforce Lead, Contact, and Account data over to the Iterable User object.
The solution provides a one-way real-time sync, pushing changes for the above Salesforce objects to Iterable every minute. It also provides an ability to run an initial or periodic backfill to get records pushed over in bulk:
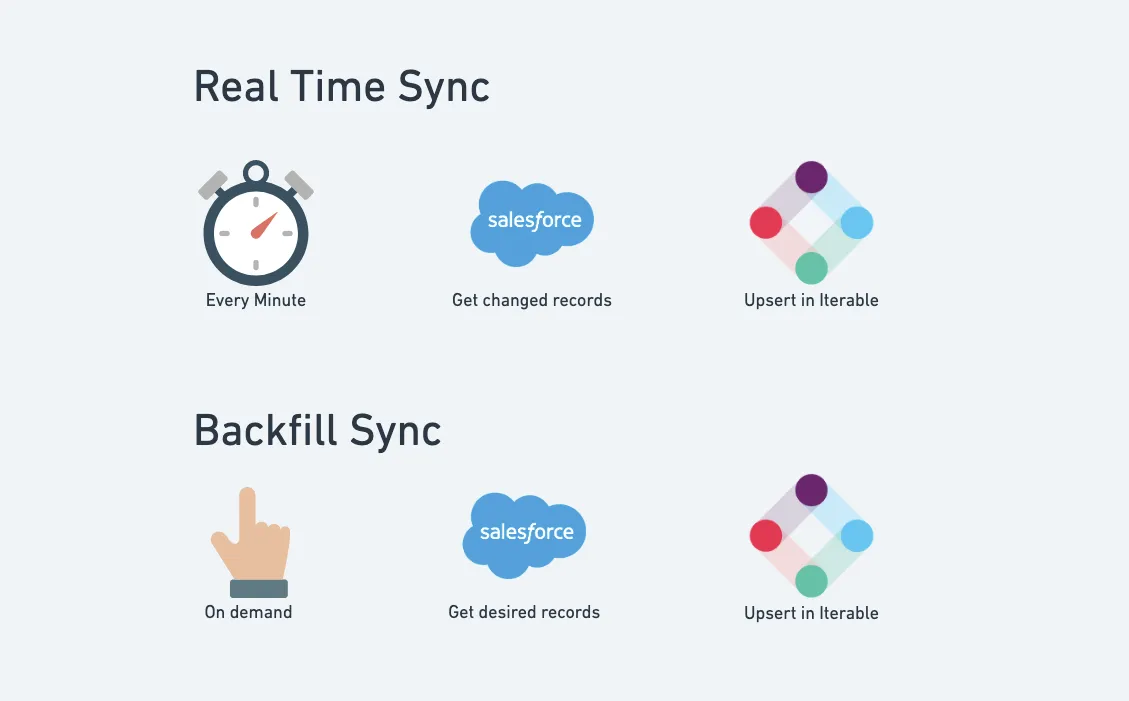
Iterable Salesforce Sync Overview
The first time I tested this process, I was backfilling 40,000 lead records and sync’d them in less than 4 minutes ;)
Real-Time Sync Architecture
Because you want data in your downstream systems as quickly as possible, the architecture is setup to sync record changes every minute.
There are three workflows unique to the real-time sync and one that is a shared with the back-fill processes.
Two of the real-time workflows listen for lead/contact records as they are created/updated in Salesforce; passing them into a queue for processing. The third runs every minute, draining the queue of these records and sending them into the shared processing workflow which does the sync work:
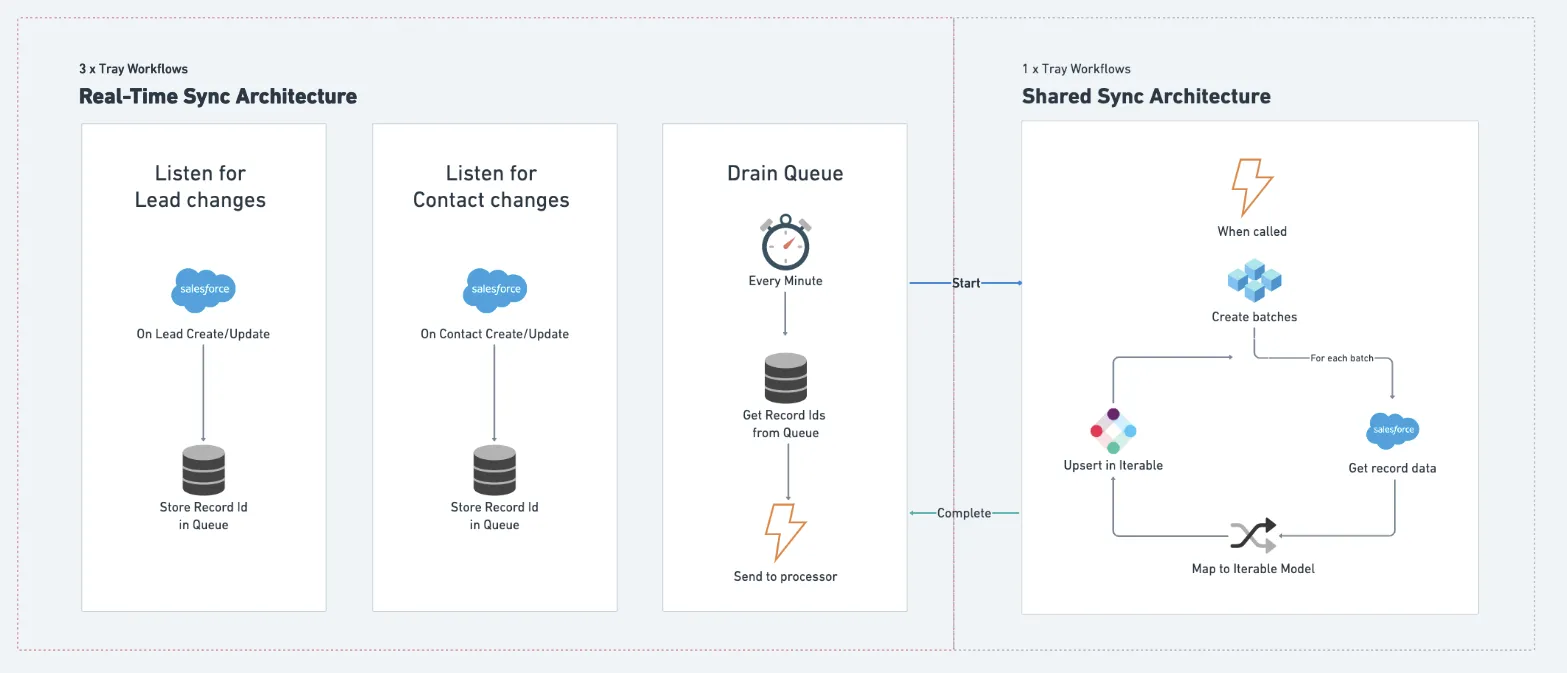
Iterable SFDC Sync Real Time Sync Diagram
Back-Fill Sync Architecture
When you’re first getting setup with a platform like Iterable, you’ll need to do a backfill of data. You may also wish to periodically do a full update to fix any data drift that’s occurred over time.
A manually triggered workflow is triggered to get multiple pages of lead or contact records from Salesforce as quickly as possible (we don’t have all day after all) to be backfilled.
Since the shared syncing workflow runs synchronously, meaning it tells the workflow calling it when it is done before that workflow moves on, we don’t call it directly via the Start Backfill workflow. This would result in the calling workflow taking far too long to sync each page of results.
We get around this by using an asynchronous workflow to act as a “coupling” to the processing workflow which allows us to process each page of records from Salesforce at nearly the same time:
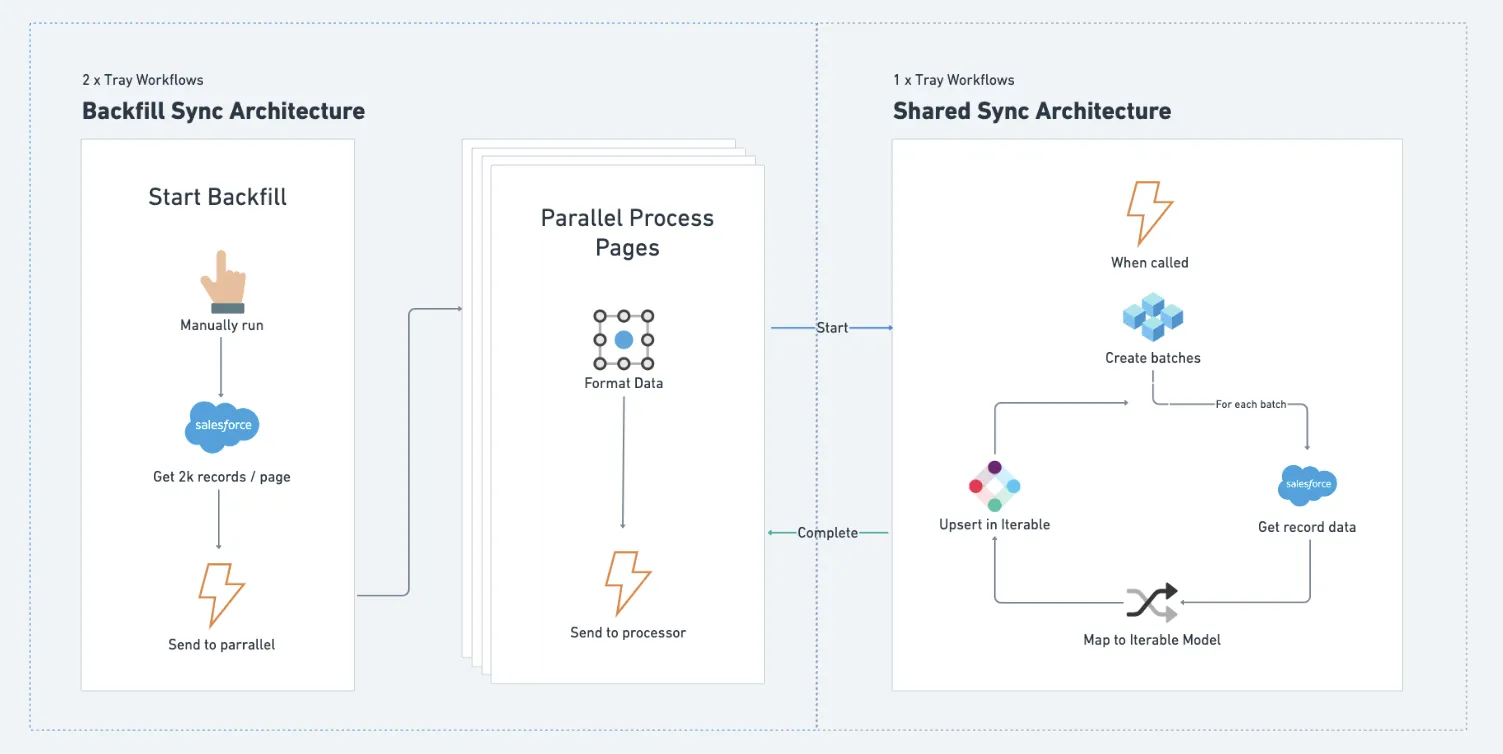
Iterable SFDC Sync Backfill Sync Diagram
CRM Syncing Workflow Build Outs
Here’s where we’ll dig into the nitty gritty details of how the architecture above is created. We’re going to look closely at each of the workflow helpers and service connectors used, so grab a coffee — no detail is left untouched.
* Don’t forget, at the end of this post you can request a copy of this solution, no strings attached (though we’d be happy to chat with you about them).
Real-Time Sync Build Out
The workflows which listen for record changes and add them to the sync queue are quite easy to setup. Each starts using a Salesforce On Record Create or Update trigger that’s set for the record type we’re interested in:
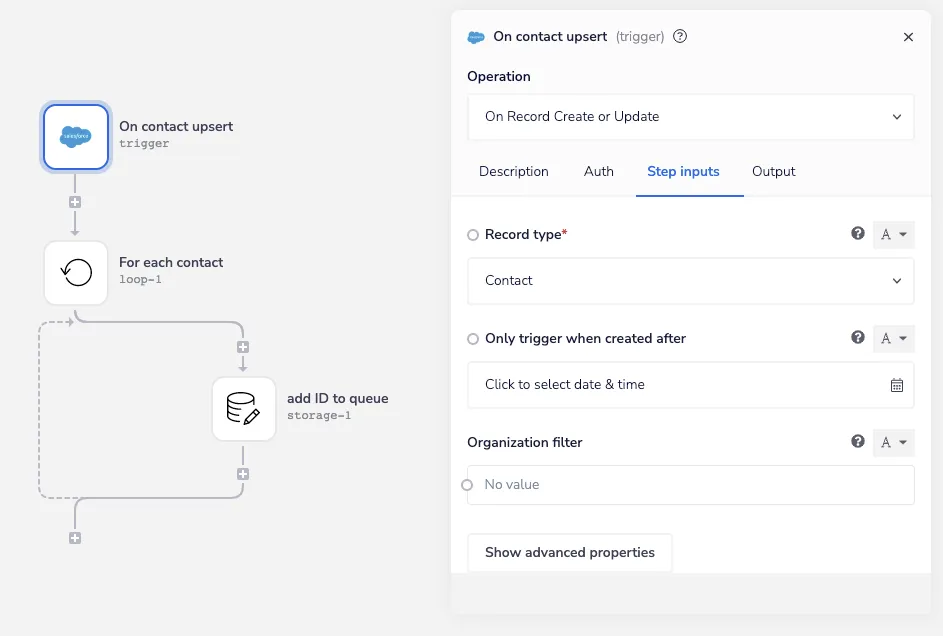
SFDC Real Time Trigger - Iterable SFDC Sync
We’re only going to push the record type and ID into the queue at this point. The Account scope setting on the add ID to queue data storage helper means any data stored under the Collection Name sfdcRealTimeSync-leadsContacts can be accessed by a separate workflow in the same workspace:
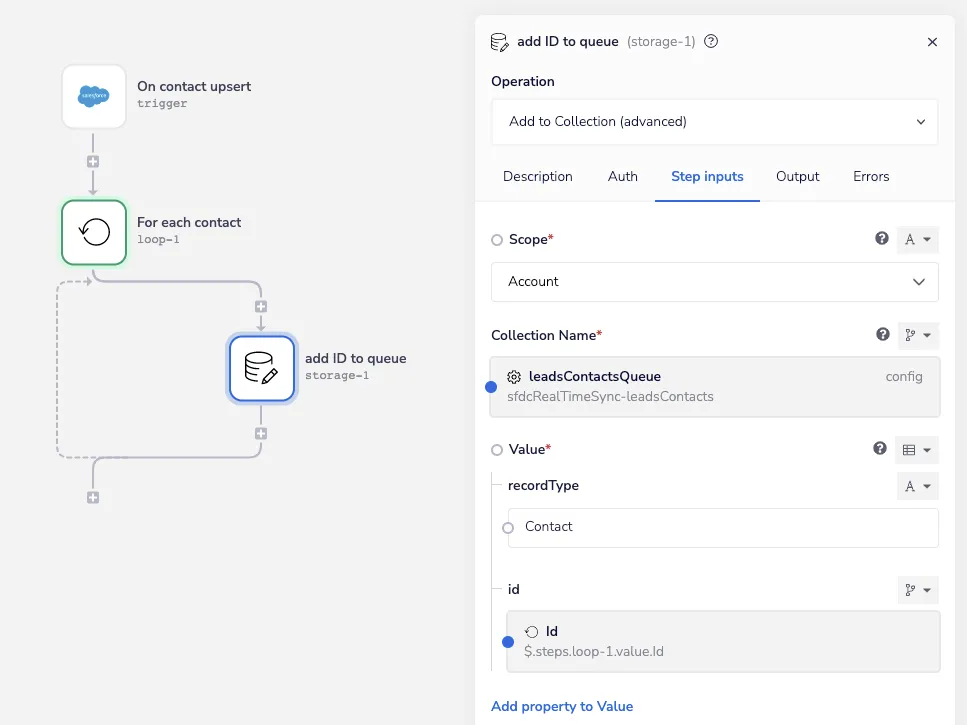
Add to Queue | Iterable SFDC Sync
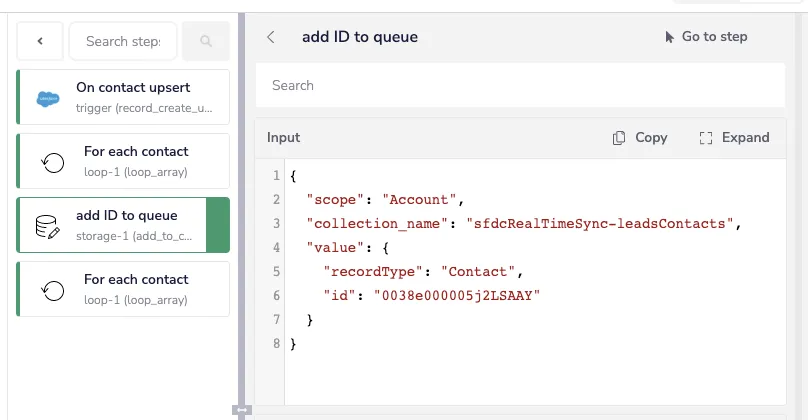
Queue log - Iterable SFDC Sync
The workflow draining the queue uses a scheduled trigger with the Interval operation set to run every minute:
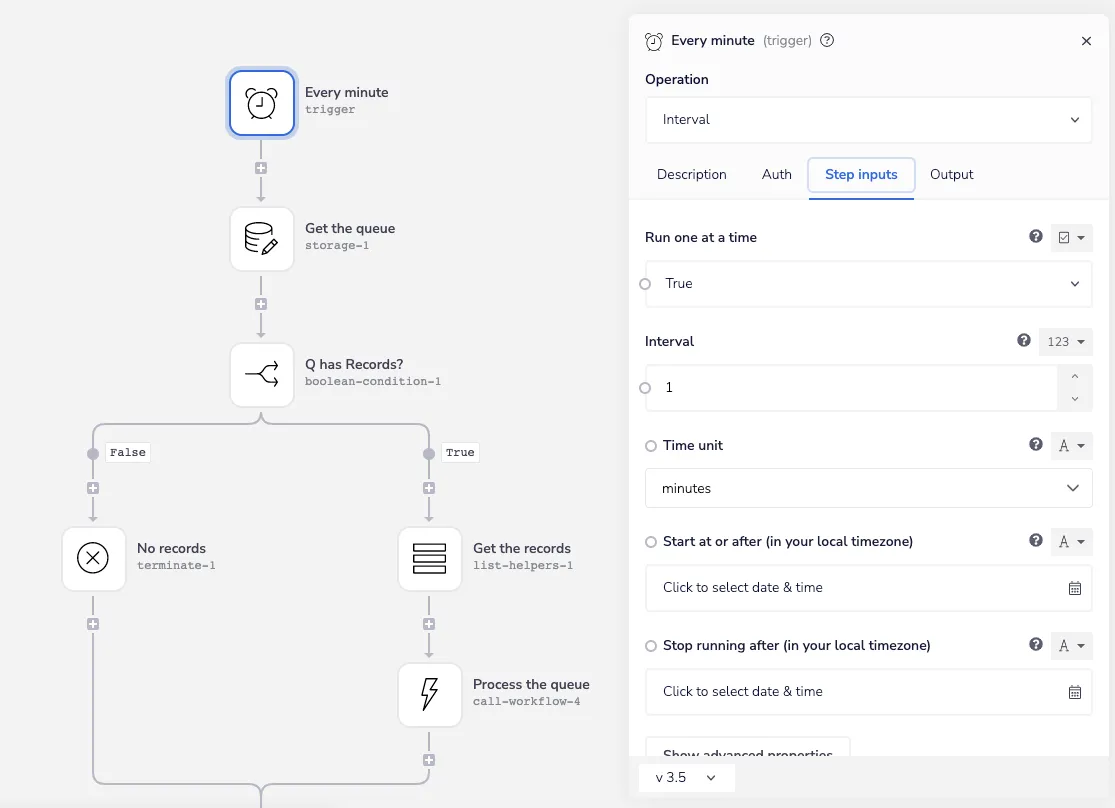
Queue scheduled trigger - Iterable SFDC Sync
The Get the queue data storage helper uses the Shift Collection operation, which fetches up to 10k records at a time. Note that this is a special operation, which both fetches and removes the data from the queue in one step:
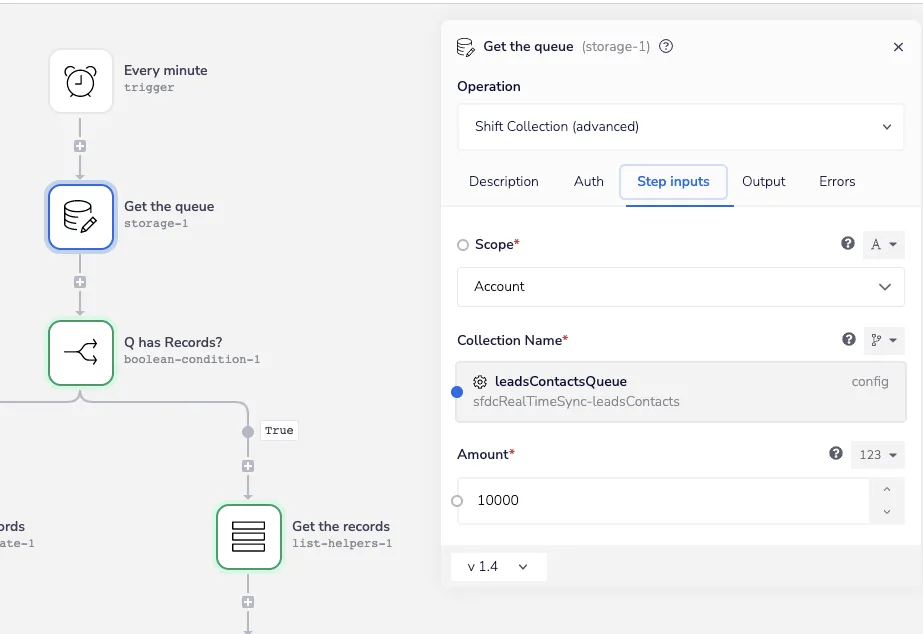
Get queue - Iterable SFDC Sync
The output of this step will contain each of the record data we’ll be syncing, along with some meta data related to the queue entry, looking something like this:
{
"values": [
{
"id": "302398",
"data": {
"recordType": "Lead",
"id": "00Q8e0000030ltnEAA"
},
"created": "2022-11-09T01:46:18.576375Z"
},
{
"id": "302399",
"data": {
"recordType": "Lead",
"id": "00Q8e0000030ltnEAA"
},
"created": "2022-11-09T01:46:26.312893Z"
}
]
}This is the reason for the additional Get the records list helper, which uses the Pluck operation to strip out that extra metadata before we pass the records list to the shared processing workflow:
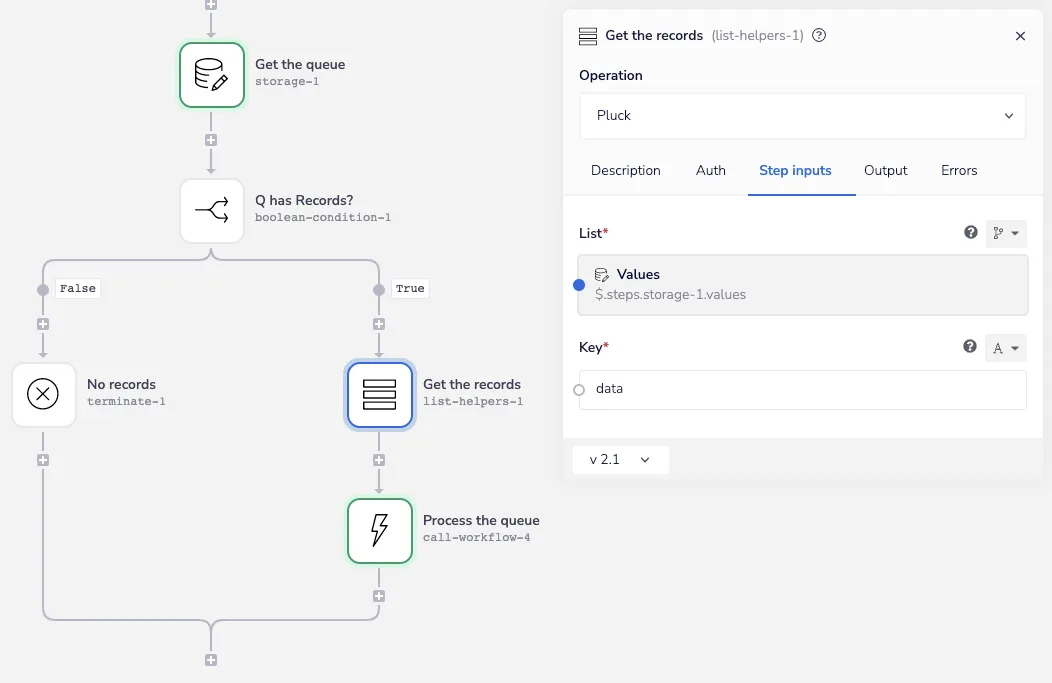
Pluck Queue - Iterable SFDC Sync
Notice we’re sending both lead and contact records out of the same queue, differentiating them with the recordType property:
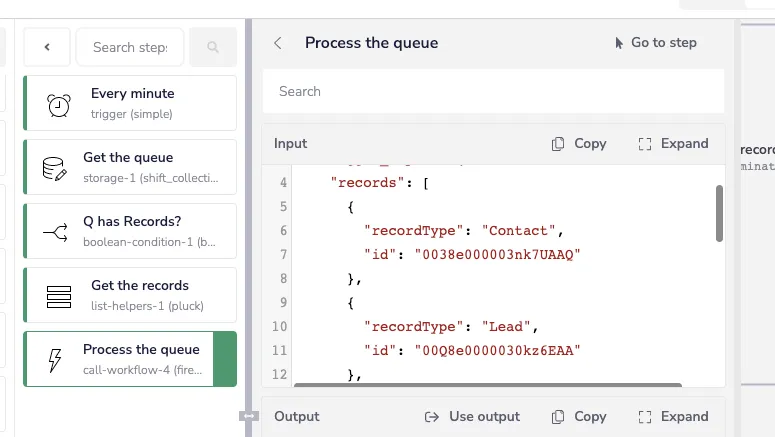
Process queue log - Iterable SFDC Sync
This concludes the workflow build out that’s specific to the real-time sync. Next, we’ll look at the backfill process that will effectively get us to this same point and we’ll round things out by diving into the shared processing workflow.
Backfill Syncing Build Out
The basis for the first leg of our backfill process is the Salesforce Pagination template. The template allows us to query Salesforce for up to 2k records/page, looping each page of results until there are none remaining.
We’ll use the Find Records operation from our Salesforce connector to get the Lead records we’re after, only returning the record ID at this stage. You can’t fully see it in the image, but records are filtered using their create date, however any number of conditions could be added to meet your specific needs:
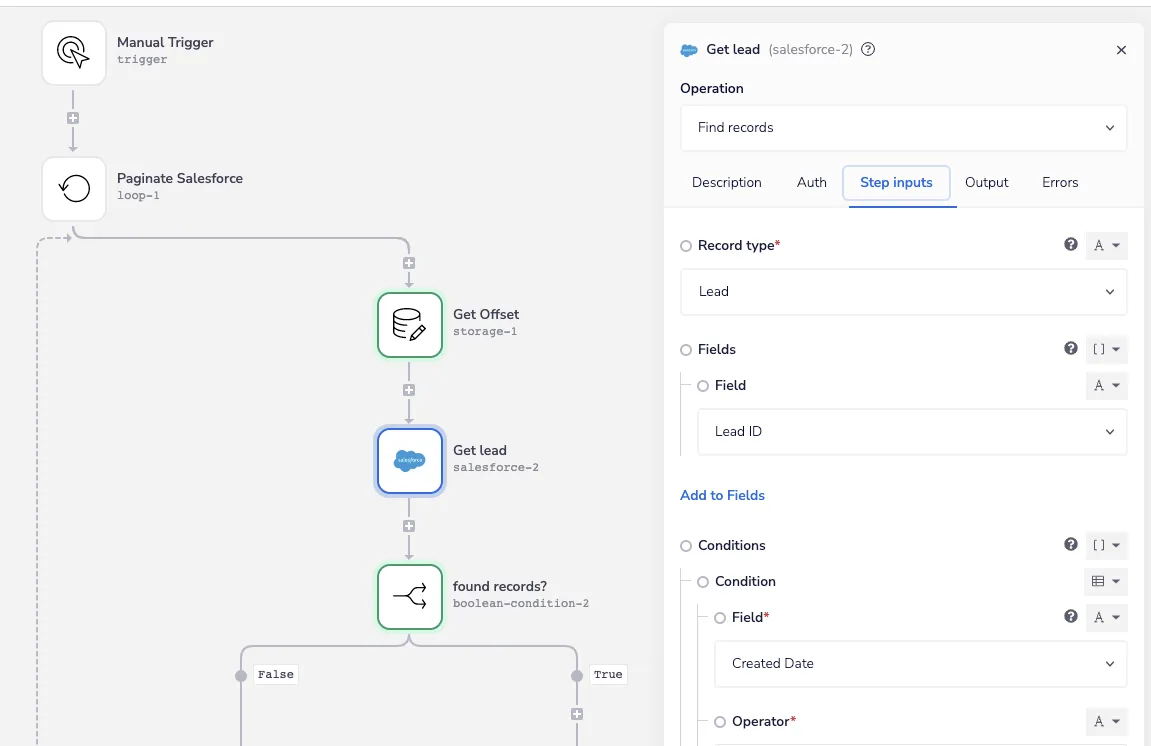
Backfill trigger - Iterable SFDC Sync
After a quick boolean check to ensure records were returned, we send each page of results to the asynchronous processor so the pagination workflow can move on to the next page of results (notice the Fire and Forget operation used):
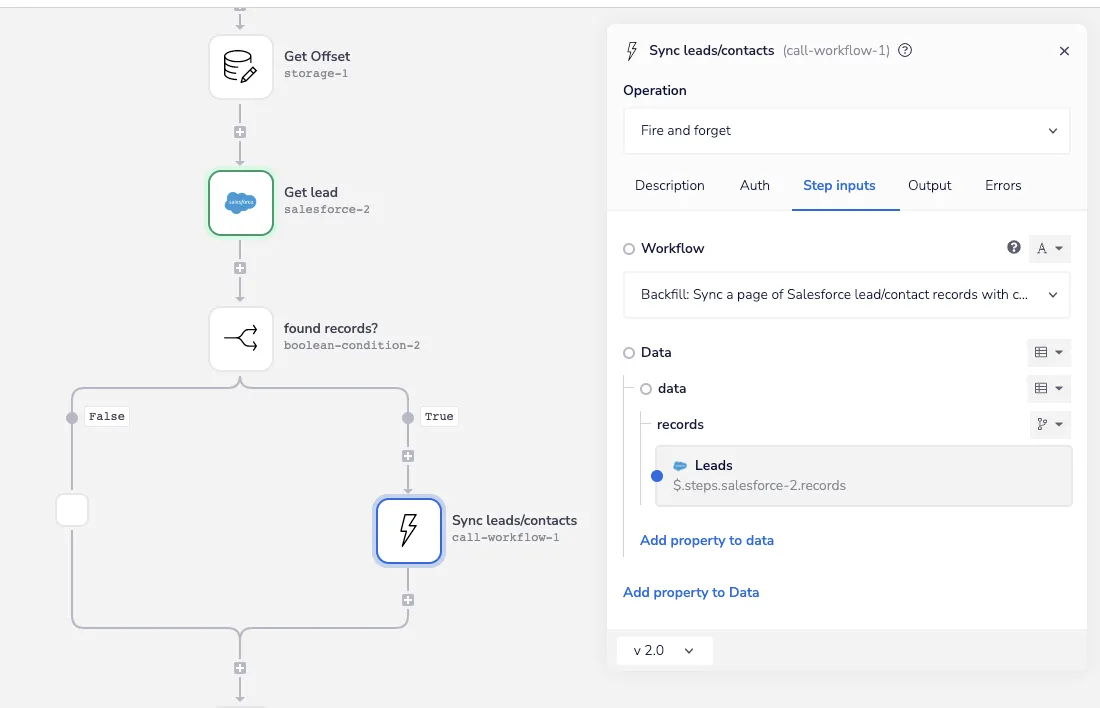
Async callable records backfill - Iterable SFDC Sync
In the async callable workflow, the first step is a handy little script helper we use that takes a Salesforce record ID and tells us what type of object it is based on the first 3 digits of the ID. We use this in all sorts of workflows and do it here because we could be backfilling leads or contacts and don’t want to have to change this manually each time:
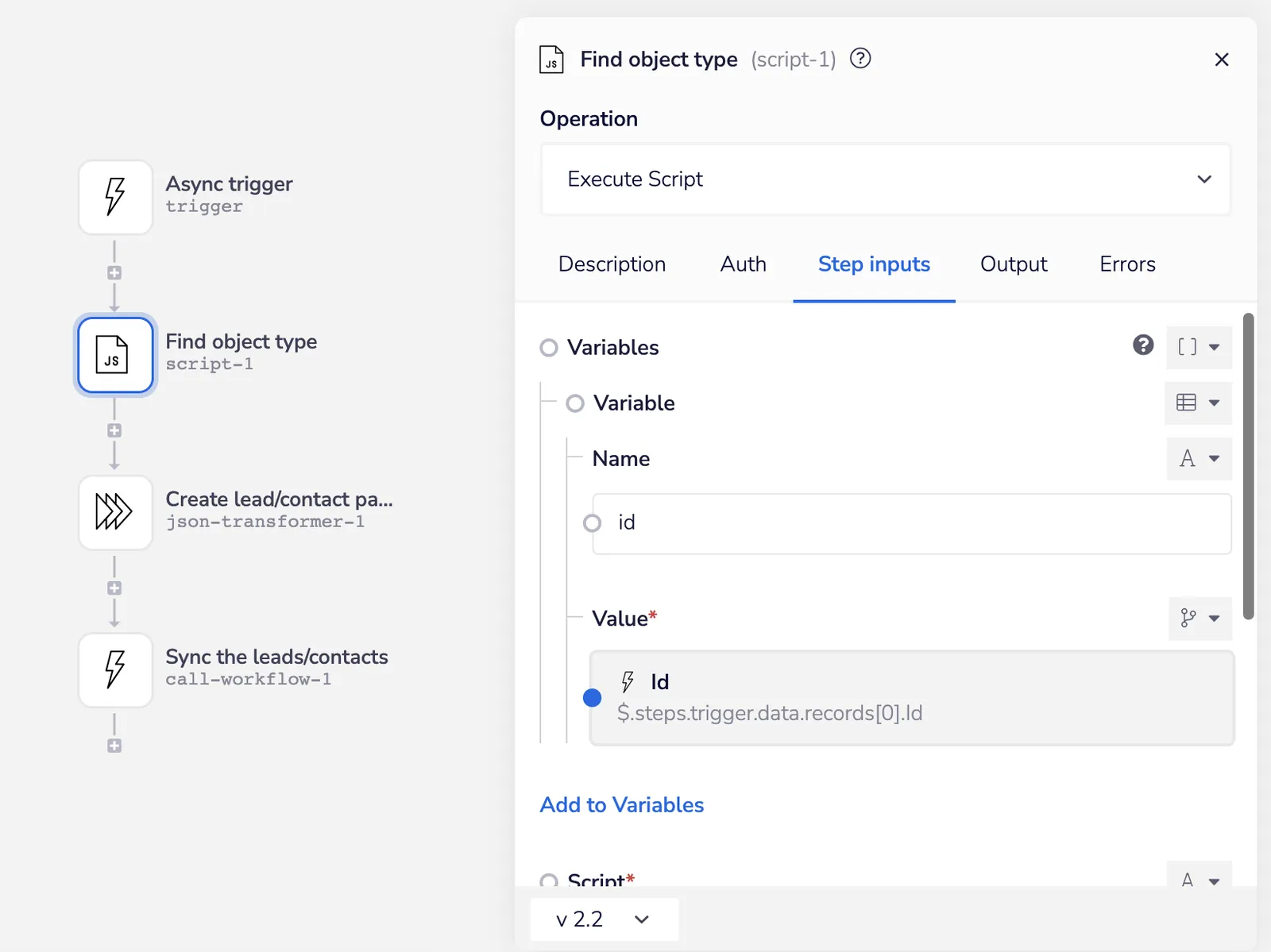
Get object type async - Iterable SFDC Sync
The Create lead/contact payload step uses the JSON transformer helper to quickly structure the provided record IDs before we send them off to the shared processor (here’s a demo of how this transformation works):
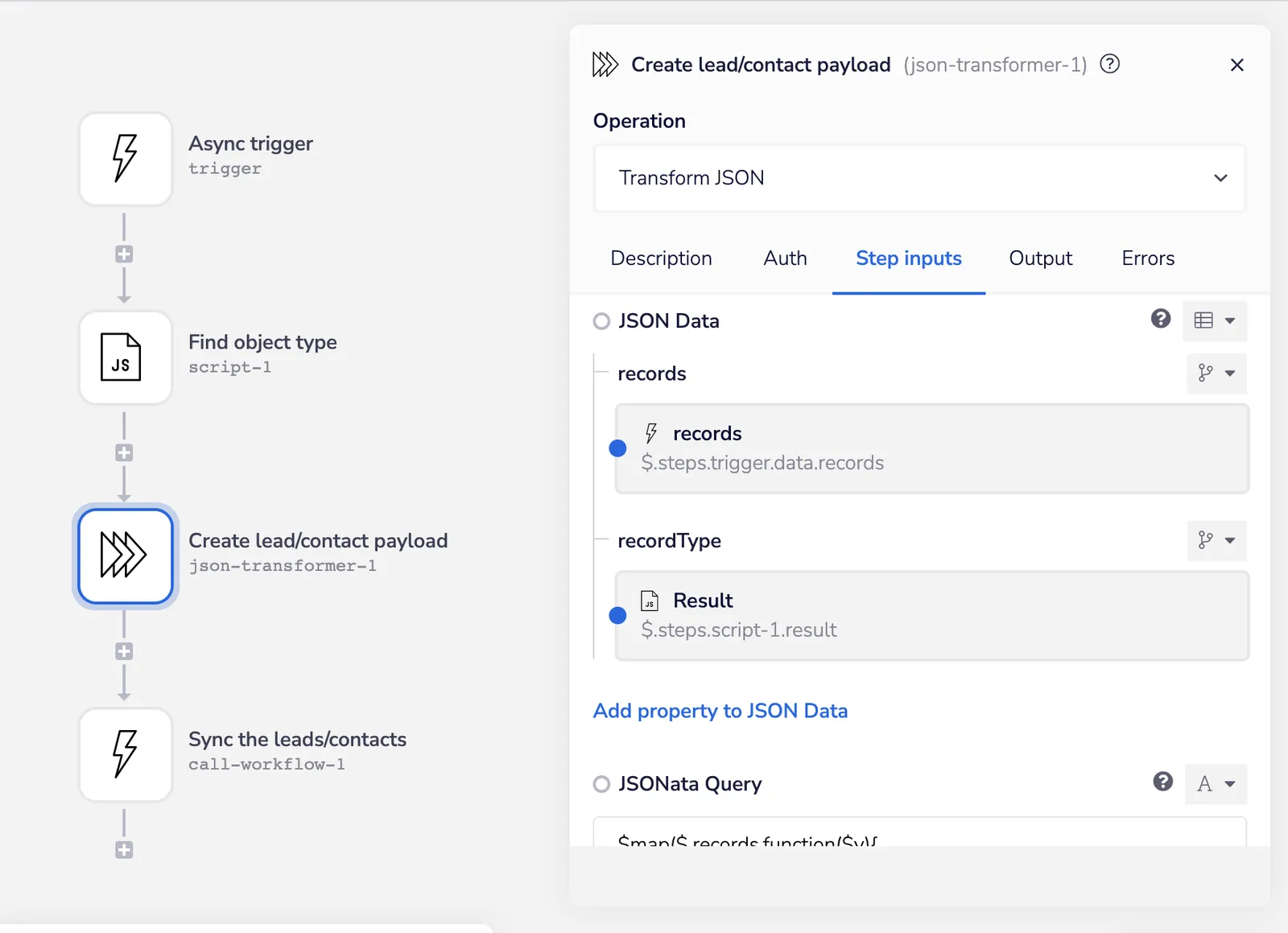
JSONata async - Iterable SFDC Sync
Records Processing Build Out
Now we’ve reached the point where both the real time and backfill processes have converged on the shared processing workflow by sending a list of records they want sync’d from Salesforce to Iterable.
The workflow is designed to process the records it receives in batches, making bulk updates in Iterable. For each batch, it queries Salesforce to get each record’s data (e.g, FirstName, Job Title, etc), then it maps the Salesforce fields to the Iterable user data model, and updates the entire batch in Iterable:
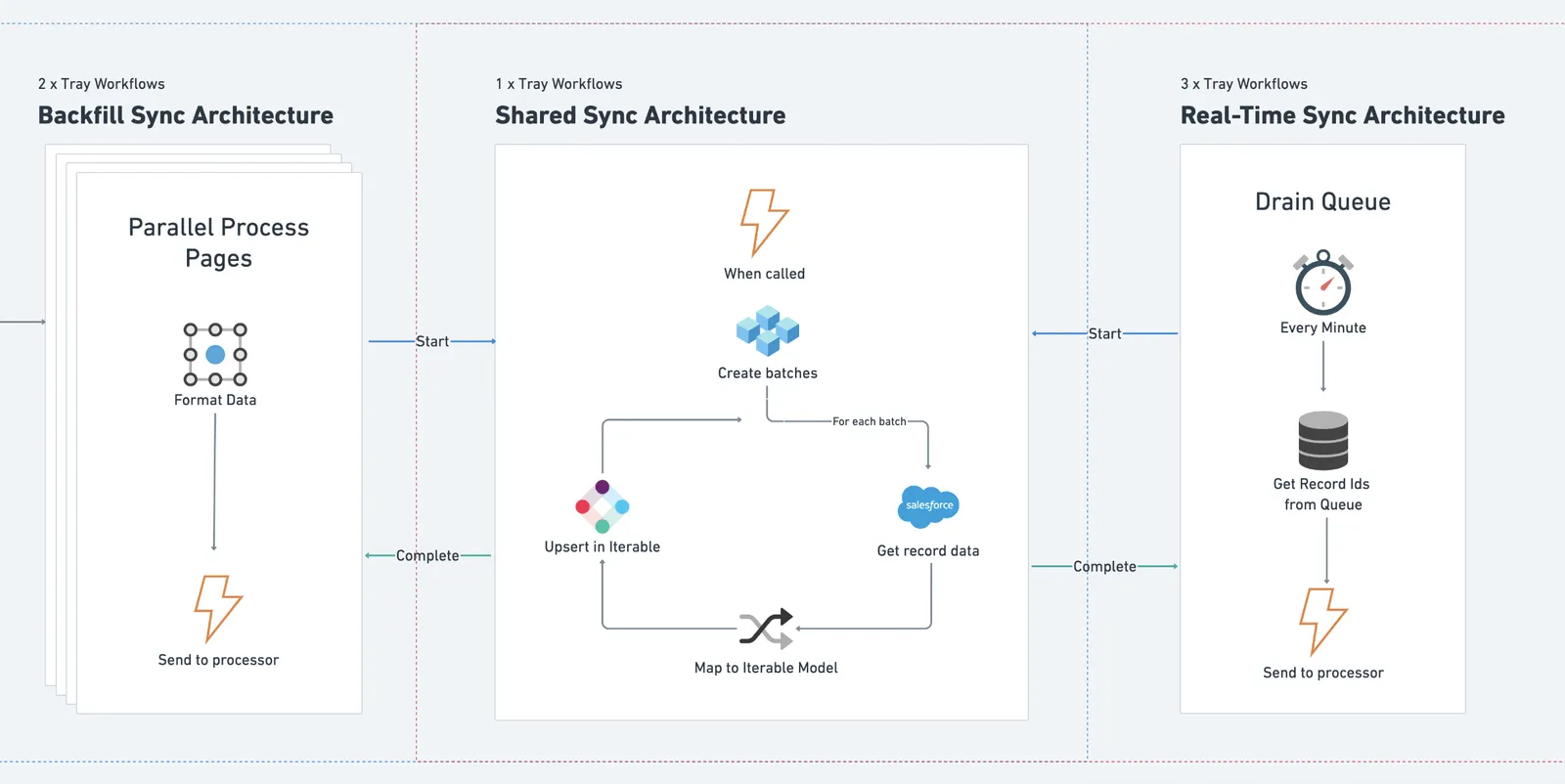
Shared architecture - Iterable SFDC Sync
In the real-time scenario, it’s often the case a record in Salesforce has been updated several times in a row, causing the same record ID to be added to the queue multiple times. For this reason, the first step in the processor is to de-duplicate the records it’s sent:
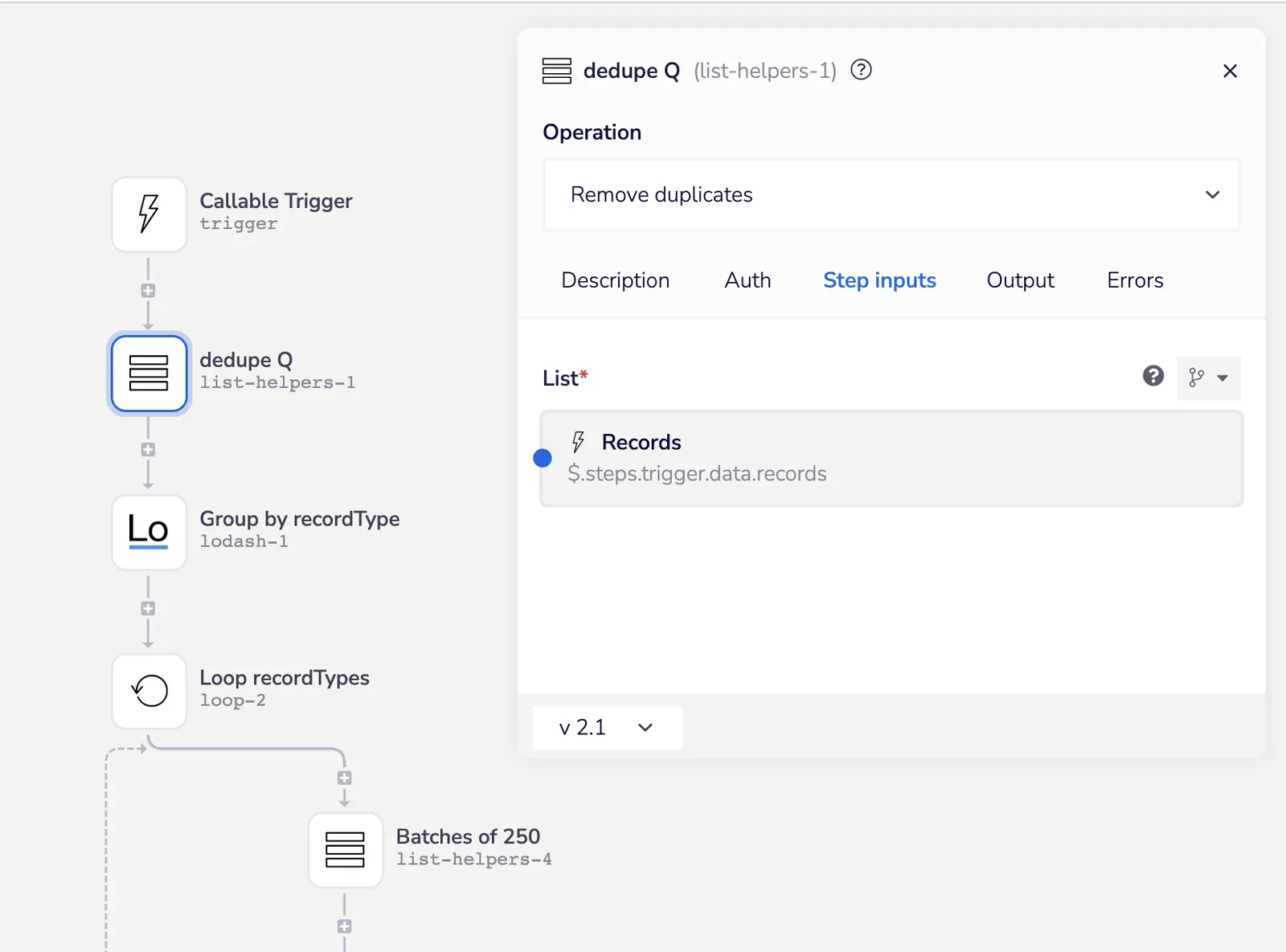
Dedupe records - Iterable SFDC Sync
Since the processor is potentially handling both lead and contact records, the groupBy Lodash operation groups the records by the their type so we can route the batch to the correct Salesforce step later in the workflow which queries for the user data:
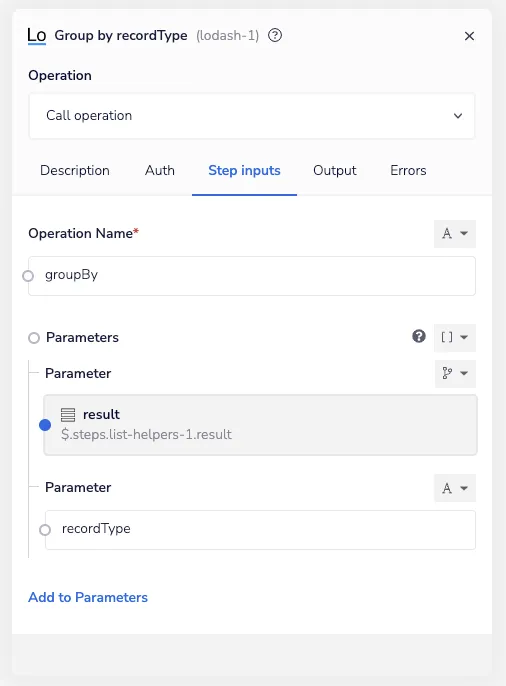
Lodash groupby - Iterable SFDC Sync
The Lodash helper generates an object containing the record types as properties and the list of records matching that type as the property’s value:
{
"result": {
"Lead": [
{
"recordType": "Lead",
"id": "00Q4H00000nab9mUAA"
}
],
"Contact": [
{
"recordType": "Contact",
"id": "0034H00002IzzWaQAJ"
}
]
}
}These properties can then be iterated over using the Loop Object operation…
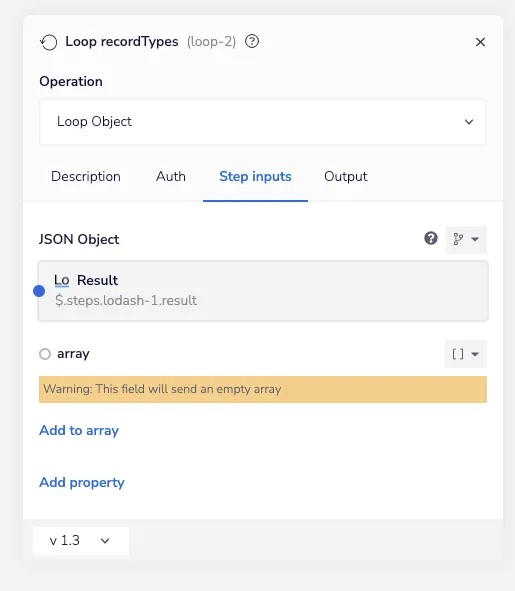
Loop records object - Iterable SFDC Sync
…which provides the list of records to sync in the value property and the type of records in the key property of the loop’s output:
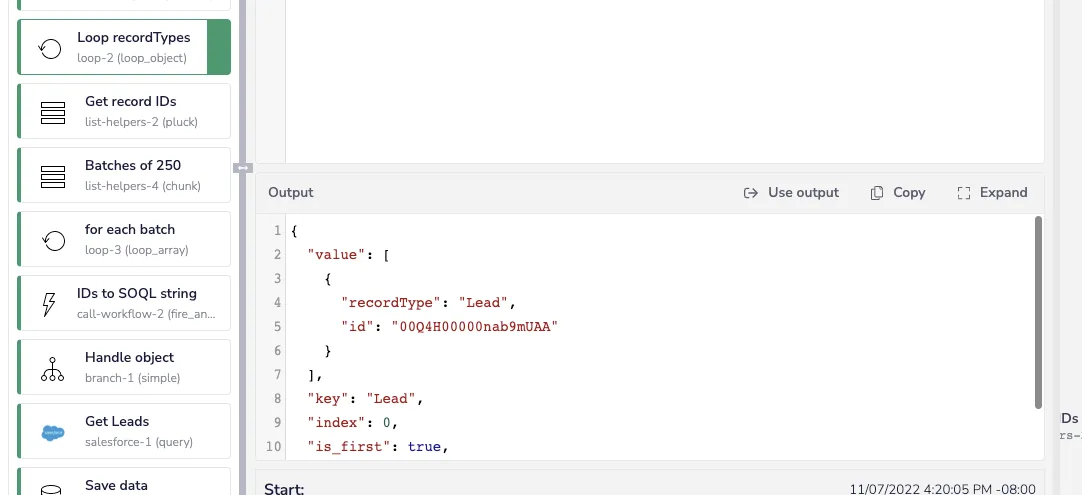
Loop object output - Iterable SFDC Sync
Since we have a distinct set of record id’s for each record type, we can go ahead and create batches using the list helper’s Chunk operation (btw, Chunk is 100% the best character in Goonies):
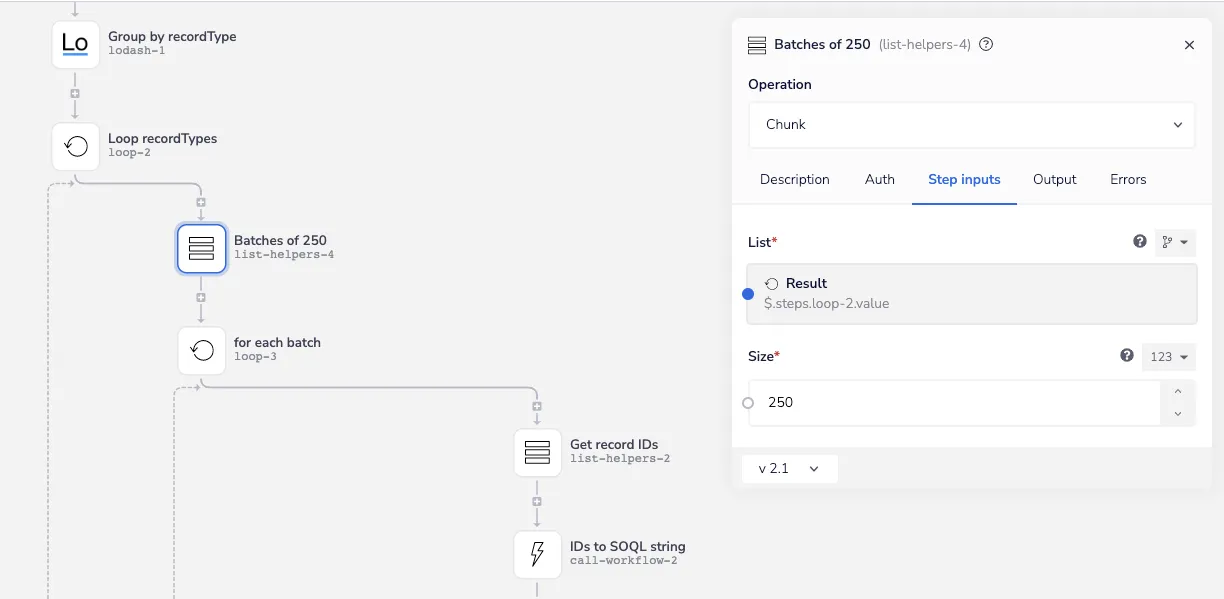
Create batches - Iterable SFDC Sync
We’re going to be using a SQOL query operation from the Salesforce connector so we can get data from multiple record types in one step via relationship queries (e.g., get the lead/contact owner or the contact’s account).
Our SOQL query will end up looking like this:
SELECT
Id
FROM
Lead
WHERE
Id in ('00Q4H00000nab9mUAA','00Q4H00000nabBxUAI')The Get record IDs step uses the list helper’s Pluck operation to pull the id property for each record out of the records collection and gives us a simple list of IDs like this:
[
"00Q4H00000nab9mUAA",
"00Q4H00000nabBxUAI"
]In SOQL, the double quotes have a reserved meaning, so we need to transform them to a single quote. We also need to remove the square brackets, returning the entire set of IDs as a string like this:
"'00Q4H00000nab9mUAA','00Q4H00000nabBxUAI','00Q4H00000nabD0UAI'"When you pass the ID’s to SOQL string callable workflow a list of Salesforce record ID’s, it returns them in proper SOQL syntax:
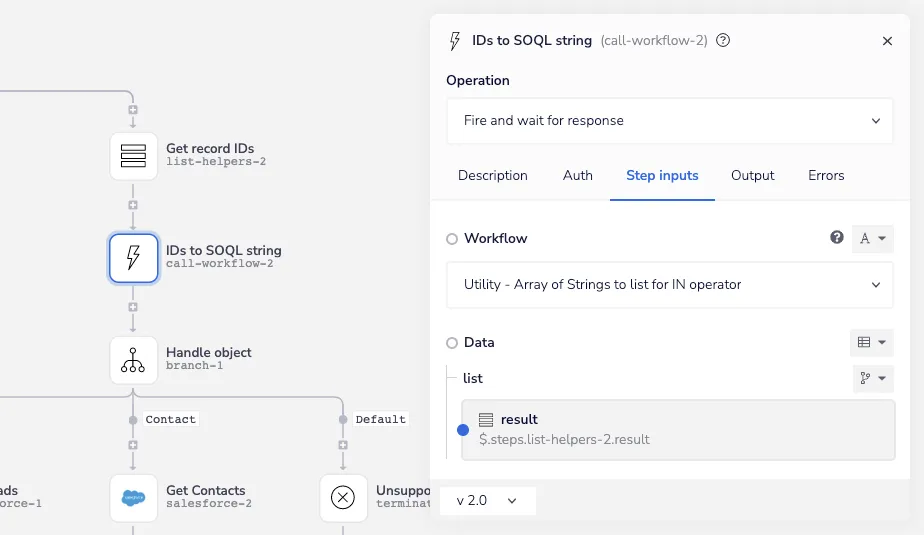
SOQL IDs string - Iterable SFDC Sync
The Handle record type branch helper routes each batch of records we’re processing to the correct SOQL queries using the record type value from the loop object operation described above.
Here I’ve highlighted how the IDs for the SOQL query’s WHERE clause are passed from the callable helper described above:
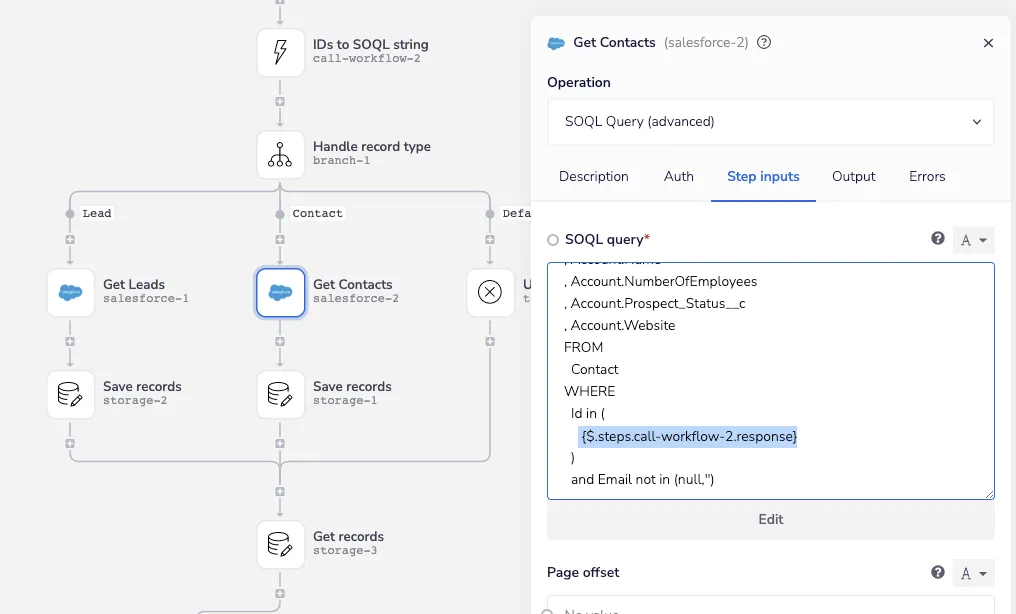
SOQL query data - Iterable SFDC Sync
The Save records data storage helper stores the now decorated records, which are then returned by the Get records storage helper. This is done because data could come from one of two potential branches:
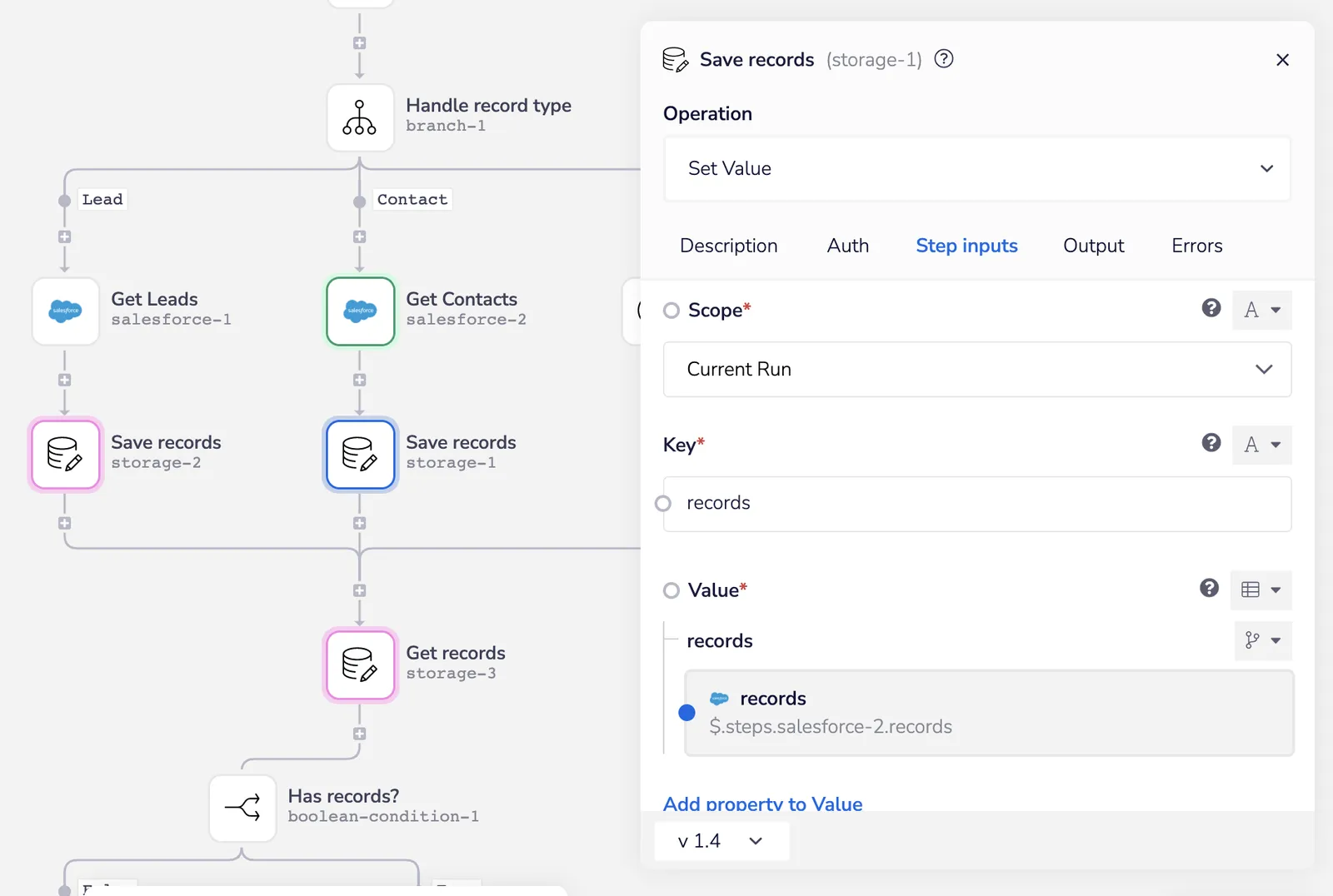
Store SOQL data - Iterable SFDC Sync
Mapping Made Simple
The goal of the mapping steps in the workflow is to transform the Salesforce lead/contact data models into the Iterable user data model. The examples below give you a sense of what each user record needs to look like before and after mapping in order to be updated via Iterable’s bulk user API:
// Before mapping
{
"FirstName" : "Niels",
"LastName" : "Fogt",
"Email" : "niels@tray.io",
"Id" : "00Q4H00000nabD0UAI",
"Status" : "3 - Marketing Qualified",
"Source" : "Paid Search",
"Account" : {
"Id": "00158000013xKVnAAM",
"Name": "Tray.io"
},
"Owner": {
"Email": "john.doe@tray.io",
"Name": "John Doe",
"IsActive" : true,
"Id": "0054H000007DMDRQA4"
}
} // After mapping
{
"email" : "niels@tray.io",
"dataFields": {
"Name" : {
"First" : "Niels",
"Last" : "Fogt"
},
"Lead" : {
"Status" : "3 - Marketing Qualified",
"Source" : "Paid Search"
},
"Salesforce" : {
"Id": "00Q4H00000nabD0UAI"
},
"Company" :{
"Name" : "Tray.io",
"Salesforce" : {
"Id" : "00158000013xKVnAAM"
}
},
"Owner" : {
"Email" : "john.doe@tray.io",
"Name": "John Doe",
"Salesforce" : {
"Id": "0054H000007DMDRQA4",
"Active" : true
}
}
}
}We can easily take the nested object structure returned by our SOQL relationship queries and turn it into the nested object structure for Iterable using the Map Objects operation from the data mapper helper.
The operation works by providing the data mapper with a mappings object, where the property names represent the “from” object structure and the property values represent “to” form they’ll be mapped into, like this:
{
"Email" : "email",
"FirstName" : "dataFields.Name.First",
"LastName" : "dataFields.Name.Last",
"Id" : "dataFields.Salesforce.Id",
"Status" : "dataFields.Lead.Status",
"Source" : "dataFields.Lead.Source",
"Account.Id": "dataFields.Company.Salesforce.Id",
"Account.Name": "dataFields.Company.Name",
"Owner.Email": "dataFields.Owner.Email",
"Owner.Name": "dataFields.Owner.Name",
"Owner.IsActive" : "dataFields.Owner.Salesforce.Active",
"Owner.Id": "dataFields.Owner.Salesforce.Id"
}While you could manage this object using the data mapper’s input field, I find using an object helper faster to edit:
Simply pass the output of this object helper to the mapper, along with the records returned from our SOQL query and away we go:
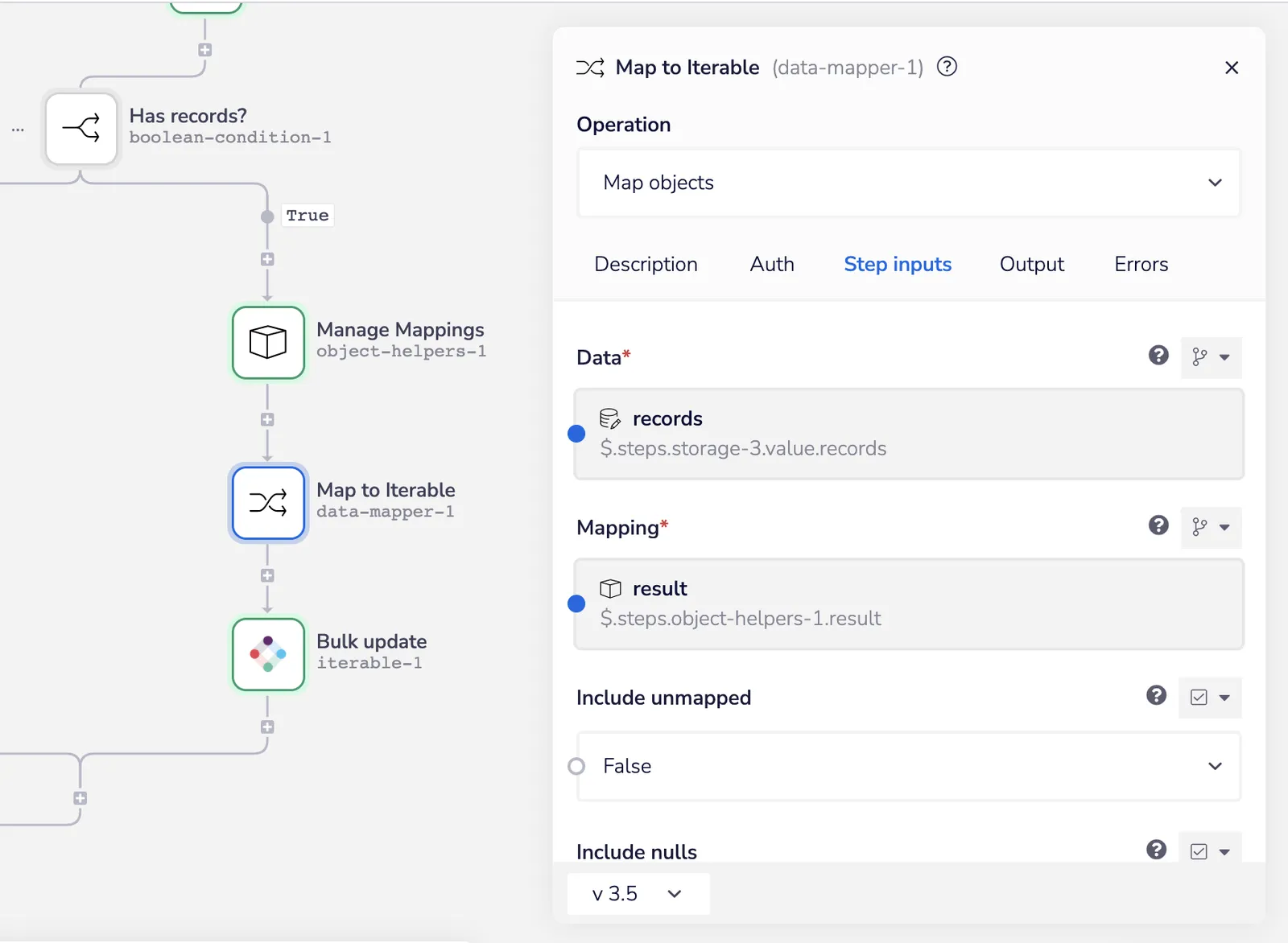
Conduct mapping - Iterable SFDC Sync
The final step is to pass the now mapped records to our bulk update call to Iterable:
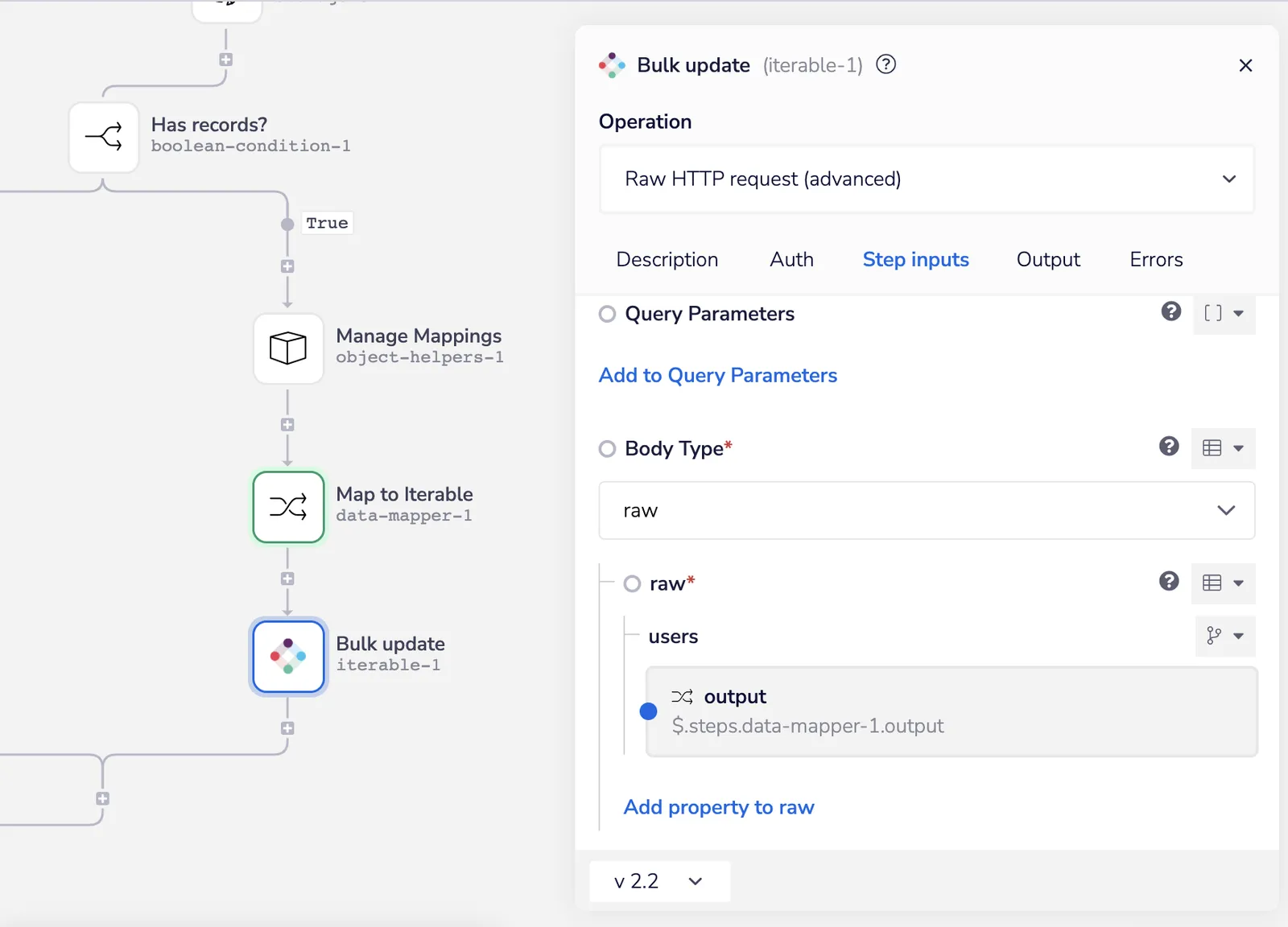
Bulk update in Iterable - Iterable SFDC Sync
Steal this solution
As promised, if you’d like a copy of this entire solution loaded into your Tray account, click the link below and we’ll get you a copy right away. If you’re not already a customer, we’ll send you an invite to a trial with everything ready to go.
Closing Thoughts
Thanks for sticking with me through this detailed breakdown — I’ll close with a few parting thoughts.
- This architecture can be used for more than just Salesforce or Iterable. Any system that offers APIs to read/write data to them could use the same basic approach, we’d be happy to show you how.
- Mastering tools like Tray means business technologists can create RevDev solutions like this far more easily, you don’t need engineering to do this.
- Further, the ability to do this gives you leverage. Leverage to choose best in breed tools, leverage to control your human resource and tech stack costs, and leverage to extend your systems far beyond what you ever thought possible.
If you’re a RevOps or BizTech leader, you need to be investing in your teams capabilities here. We’re here to help you get there!