

For the past 18 months, people have been experimenting with AI. It’s easy, fun, and often very useful when it comes to helping with day-to-day tasks (for instance, I used GPT-4 to suggest the format for this blog post).
However, actually implementing AI within your business processes is challenging and, if not done properly, can lead to tricky situations – as Air Canada recently discovered when they were held liable for bad advice provided by their chatbot.
Successfully infusing AI within your organization can be massively beneficial as we’ve seen recently with Klarna’s AI assistant handling over two-thirds of customer conversations in its first month.
How have Klarna seen success with their support agent and managed to avoid potential AI pitfalls? This is likely due to their implementation of a Retrieval Augmented Generation (RAG) pipeline, ensuring their AI assistant provides accurate information and takes the correct actions when handling customer queries.
So if you…
- Haven’t got a team in place implementing AI solutions throughout your organization
- Haven’t heard of a RAG pipeline before and how it can massively reduce errors when using AI
- Want to make your support teams as efficient as Klarna’s (who are predicting an additional $40 million profit in 2024 as a result of implementing an agent)
…then this blog post is for you.
I’ll briefly explain what a RAG pipeline is and how it ensures reliable results. Then, I’ll talk through how the Tray Universal Automation Cloud is the perfect platform to develop a nimble RAG pipeline without being locked into a particular vendor. Finally, I’ll dive into how we’ve been using various data sources and Large Language Models (LLMs) to completely transform our processes with Tray-powered RAG pipelines.
This is all functionality that is available right now with Tray, so I’ll also offer guidance on how you can get started and implement advanced AI processes within your organization in just a couple of weeks.
You can also see me chat about our intelligent knowledge agent and show it off with others from the Tray product team in a recent LinkedIn Live event. Watch it on-demand.
Retrieval Augmented Generation (RAG) pipeline explained
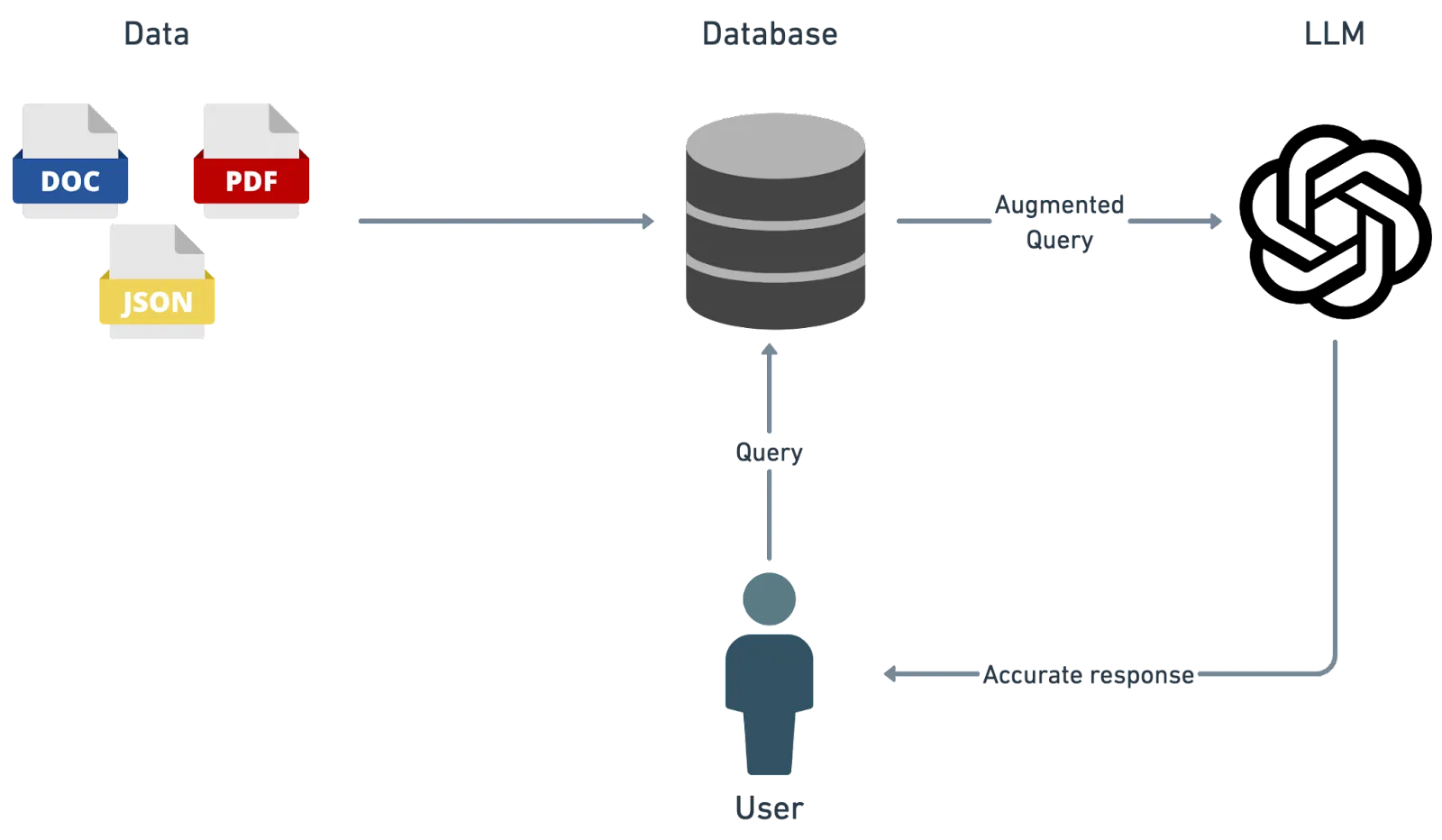
A Retrieval Augmented Generation (RAG) pipeline is an advanced AI tool that intelligently combines information retrieval with generative AI to increase and reduce hallucinations (incorrect or misleading results that AI models generate). Think of it as a smart assistant that first finds the most relevant information across a vast database, much like an adept librarian knowing exactly which books to recommend based on a particular query. Then, it acts like a skilled storyteller, using this information to craft detailed and accurate responses.
Here’s the streamlined process:
- Retrieval: It searches a large pool of data to find pieces closely related to the query.
- Augmentation: The original query is augmented with the data retrieved
- Generation: It produces a final, comprehensive answer that’s not just relevant but also accurate
What sets a RAG pipeline apart, particularly in the context of preventing the spread of incorrect information, is its ability to fact-check against a wide range of sources in real time. This capability is crucial, as evidenced by the differing outcomes experienced by Klarna and Air Canada. In situations like these, the ability of such a pipeline to generate accurate, context-aware responses could significantly enhance customer trust and satisfaction. Perhaps most importantly, knowledge agents powered by a RAG pipeline can be instructed not to answer a particular query if the augmentation step doesn’t return any relevant results. By ensuring that the information generated is both relevant and verified, businesses can avoid the pitfalls of disseminating misleading or incorrect data. In doing so, they safeguard their credibility whilst improving the efficiency of their support teams.
In summary, a RAG pipeline offers businesses a powerful way to harness AI for accurate, efficient, and reliable information generation, making it an invaluable tool for anyone looking to enhance their operations and customer service with cutting-edge technology.
Now, let’s dive into building one.
intelligent knowledge agent blog image 1
Building a RAG pipeline on Tray
A RAG pipeline ensures an LLM has access to data that will help it answer a query, making knowledge agents trustworthy and reliable. Next, I want to show you why Tray is perfect for building RAG pipelines. With Tray’s flexible and powerful platform, you can:
- Easily ingest data from hundreds of different sources using our extensive library of connectors.
- Switch out LLMs and databases seamlessly to avoid being locked into a particular vendor, giving you complete control over quality and cost and the ability to quickly switch in newer, more power models and infrastructure
- Develop entirely in Tray’s low code workflow builder without any need for AI experts or experienced AI engineers.
- Centralize your AI - stop relying on each of the different interpretations of AI that the vendors you use have adopted
- Build once and deploy anywhere
- Integrate AI within your processes
Check out our documentation for a deeper dive into building an AI knowledge agent on Tray.
Why build a RAG pipeline using a modern iPaaS
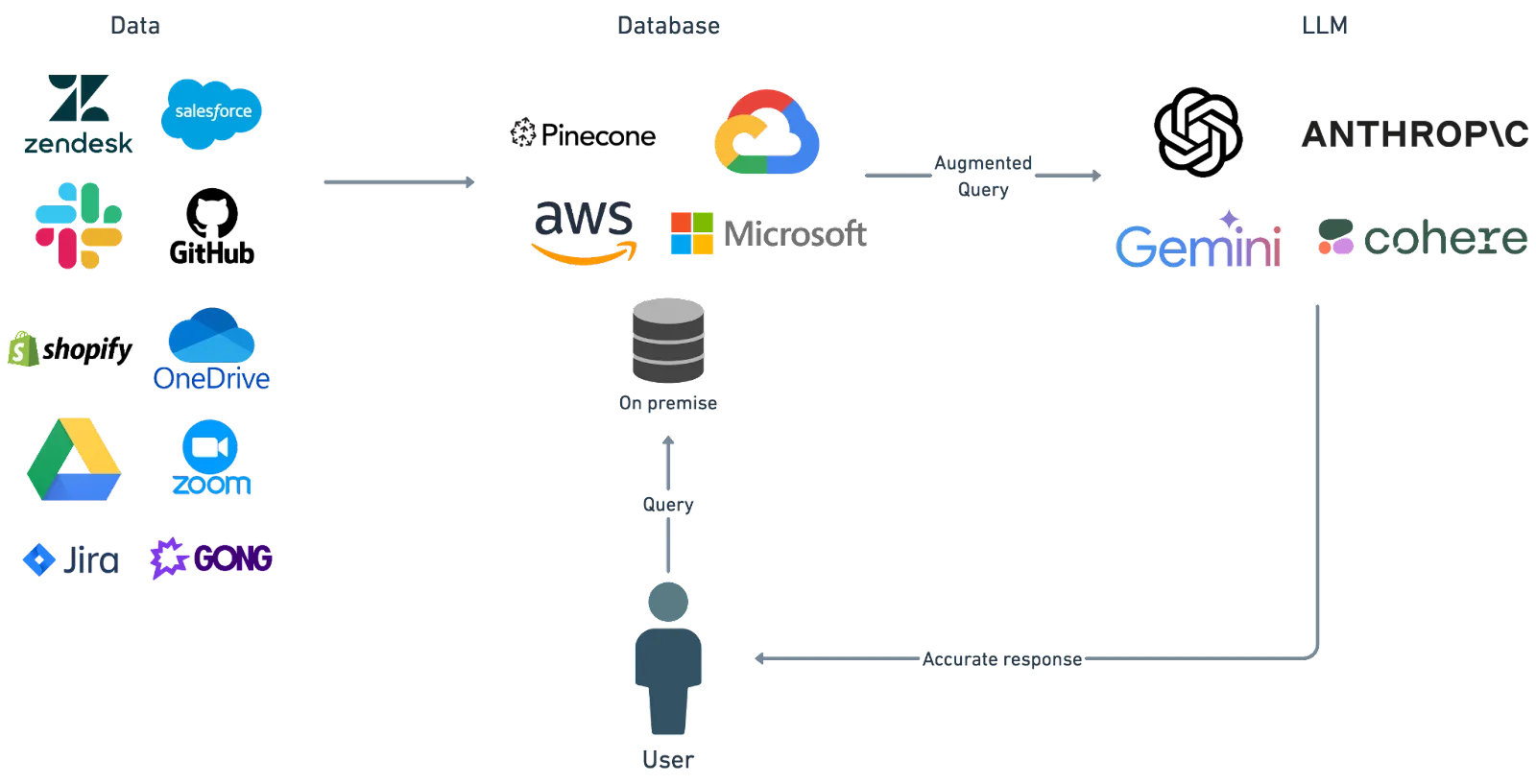
Let’s take the diagram from above and enhance it to demonstrate why Tray is perfect for building a RAG pipeline:
intelligent knowledge agent blog image 2
Data
Tray makes ingesting data to power your RAG pipeline incredibly easy. You can use our extensive connector library to pull in data from a wide range of sources to build a comprehensive picture of your organization and to provide LLMs with a rich source of data to answer incoming queries. Think about a repository of information made up of support tickets, call transcripts, documentation pages, and community feedback made immediately available to your support teams.
Pulling in data from a new source takes minutes on Tray. Additionally, you can ensure the data remains up to date by setting up subscriptions within your sources. These subscriptions automatically route new data to your pipeline for instant ingestion and accessibility for a knowledge agent powered by the pipeline.
Database
In addition to a vast library of connectors for data ingestion, Tray also has comprehensive support for storing that data in a wide range of databases. We offer support for specific vector databases like Pinecone but also for cloud providers and generic on-premise databases so you can store the data wherever you like.
LLM
Tray’s range of LLM support means you’re not tied down to a specific vendor and, therefore, have complete control over your quality and costs. Seamlessly swap out LLMs or use a range of LLMs simultaneously. We already have specific connectors in place for a wide range of the most popular models (check out our OpenAI, Cohere and Anthropic connectors) and have teams dedicated to ensuring that the latest models are available as soon as possible.
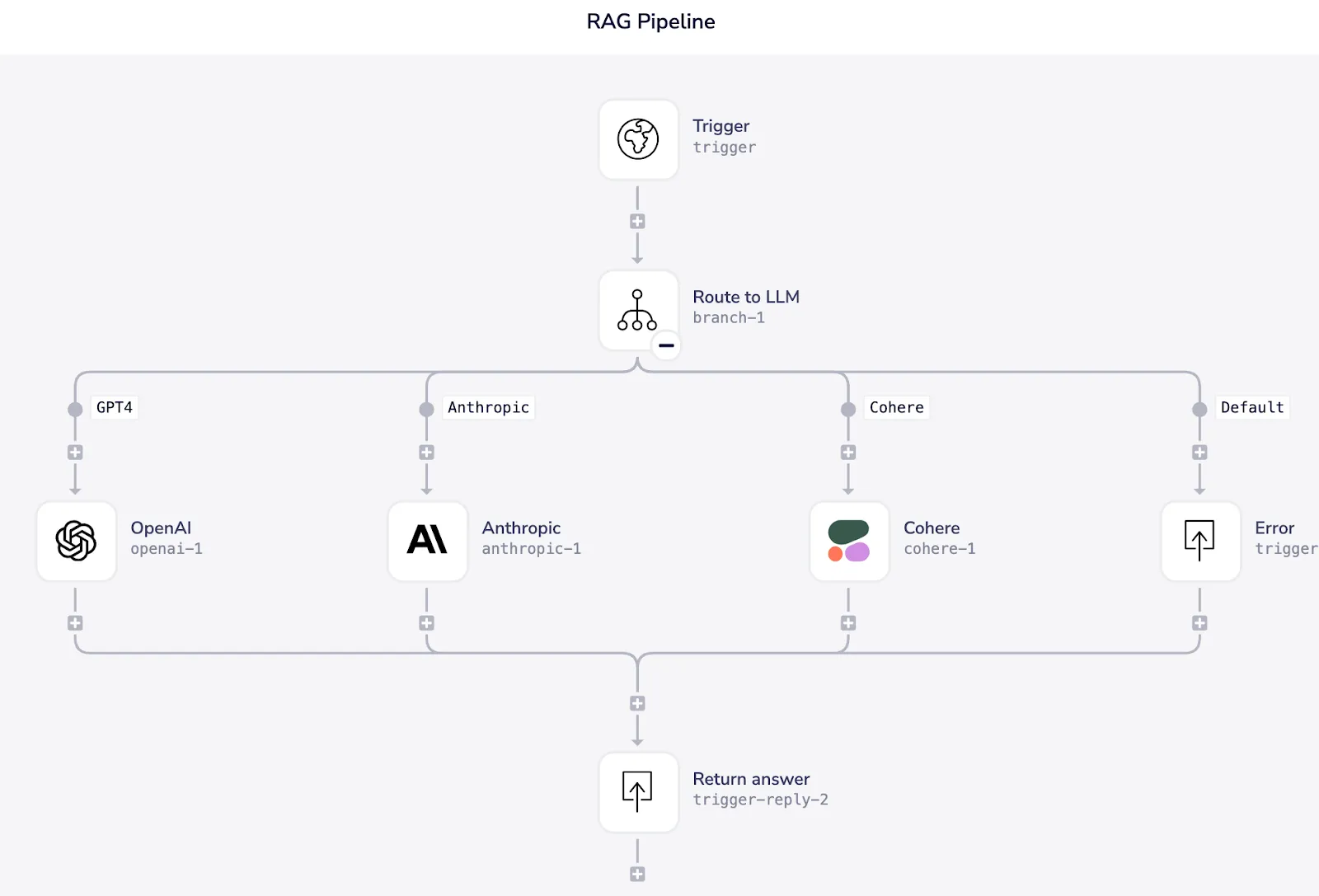
Tray’s low code workflow builder means you can get to a point where your knowledge agent is delivering value quickly without having to extend your engineering teams or bring in AI experts. Below is a workflow built on Tray that is routing a query to different LLMs depending on a particular parameter in the request. This can be set up in minutes and shows why Tray is perfect for swapping out different vendors and avoiding being locked in.
intelligent knowledge agent blog image 3
Centralized vs Localized AI
All of the tools we use today implement their own interpretation of AI. On the surface, this is very useful. Who doesn’t want to read a quick summary of a call recording rather than watching the whole thing? These are all localized AI implementations that may save us a bit of time as individuals or as a team but don’t do much in terms of making business processes more efficient. Your call recording software doesn’t have information about your support tickets and your ticketing software has no call recording summaries. Therefore, any RAG pipeline or AI process using data exclusively in these services will have access to a very narrow information set. With Tray, you can develop a centralized AI implementation that can be quickly populated with information across your business and instantly enhanced when new information becomes available.
Integrate AI within your processes
Once you have your centralized AI, Tray makes it incredibly easy to deploy it anywhere and integrate within your existing business processes. Having a knowledge agent that can answer questions is useful but what you really want is an agent that can get stuff done. With Tray, you can embed your agent within a customer support flow where it can answer support questions when it’s confident about the answer, or draft an answer and get a customer support team member to check before responding when it is not confident. This is just the tip of the iceberg - with Tray’s range of connectors and API management functionality you can integrate your agent within almost any process.
So there you have it - Tray’s wide range of connectors and flexible low-code building experience is the perfect combination for quickly developing RAG pipelines that can power knowledge agents, enabling you to centralize AI within your organization and make your teams more efficient. Everything I’ve gone through so far isn’t just hypothetical - it’s exactly what we have done to develop our own RAG pipelines and I’m going to walk you through how we got a knowledge agent live in just a couple of weeks.
How are we using RAG pipelines and intelligent knowledge agents
There is nothing hypothetical in this blog post. It’s all possible to do right now on the Tray platform because that is exactly what we have done. In just 2 weeks, we were able to:
- Build a RAG pipeline that contains data from our entire documentation site
- Build a process that updates the information available whenever a change is made to our documentation
- Store all of this data in a brand new vector database
- Develop query pipelines with 3 different LLMs that can be used interchangeably for augmentation and generation
- Expose the query service as an API
- Build an extension to Merlin (our intelligence layer) into our documentation site that is powered by the RAG pipeline we’ve developed
This was all done exclusively by our documentation team (no engineers or AI experts) who weren’t familiar with RAG pipelines before they started. Let’s break it down step by step.
intelligent knowledge agent blog image 4
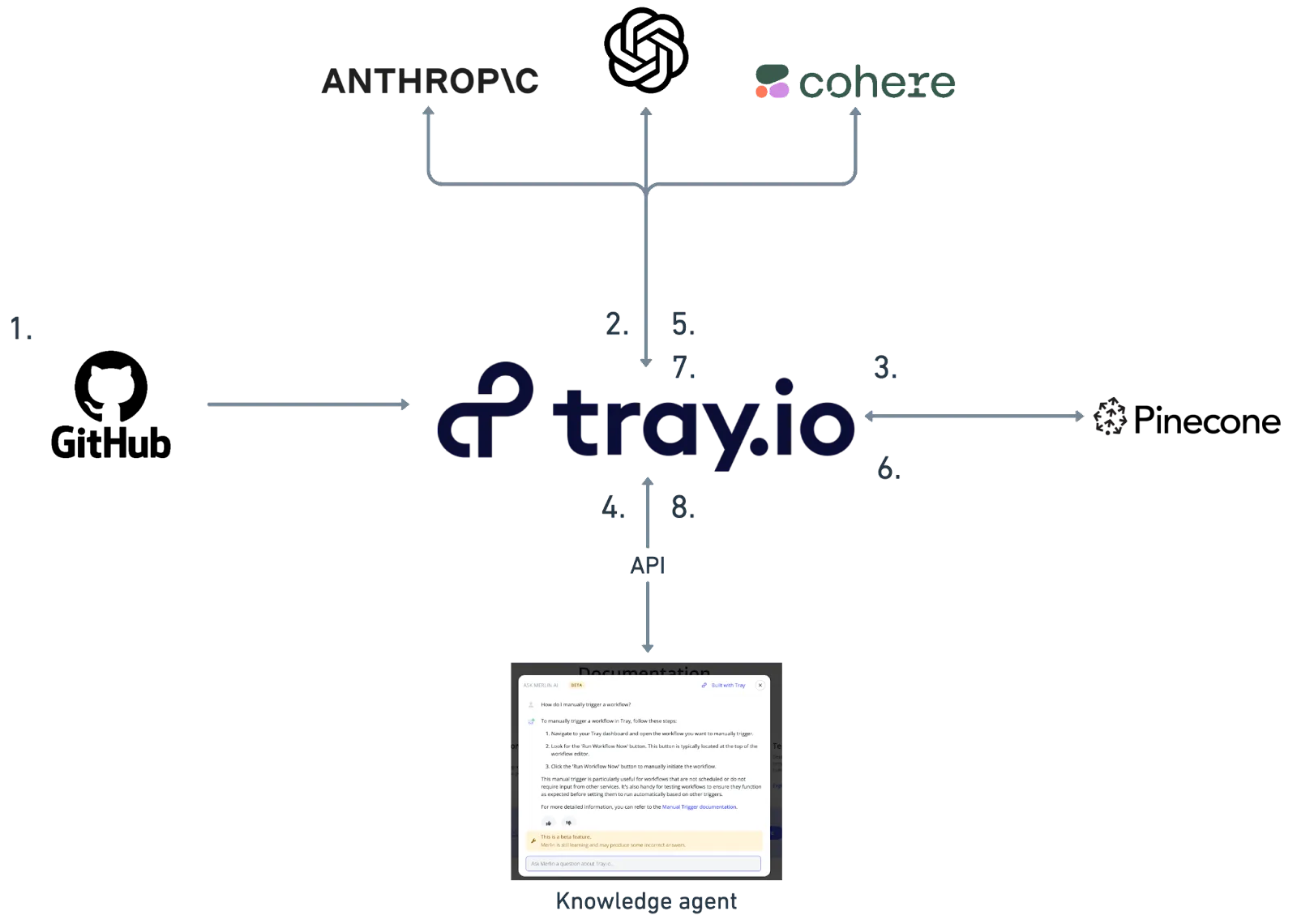
- First, the team set up a pipeline to ingest all of our docs content. This is set up as a large initial run. Then, there is a subscription in place that captures new content when it is made public. Tray processes the data and chunks it up so that it’s ready for the next step.
- The data is passed to an LLM to create embeddings which enable us to store the data in a way that makes it easy to locate when a query is received. Each of the Tray connectors for the LLMs used have a specific operation for creating embeddings so it’s very easy to set up
- The embeddings created in the previous step are stored in a vector database along with the information that they represent. The Tray Pinecone connector is set up so you can achieve this in a single step - just pass in the output from step 2.
- We’re now ready to receive queries! The Tray platform allows you to expose functionality built in Tray workflows as APIs and that is exactly what we did. The query pipeline is exposed as an API that is used to power our knowledge agent. The API takes a query and an LLM as parameters.
- Tray routes the query to the specified LLM using the parameters provided in the call to the API. The LLM uses the query to create embeddings just like in step 2. These embeddings are passed back to Tray.
- Now instead of loading these embeddings into Pinecone, Tray uses them to query Pinecone. Pinecone will return a bunch of results relevant to the query.
- Tray takes these results and augments the initial query with a prompt containing the results and the context in which the LLM is to operate (in our case as a support agent to answer questions about using the Tray platform). The Tray LLM connectors make it very easy to configure additional rules. For instance, we’ve got our agent set up to not answer questions when it is not provided with relevant results which protects our customers from receiving inaccurate information (LLMs returning inaccurate or irrelevant information are often referred to as hallucinations and this is exactly what a RAG pipeline prevents).
We get the answer back and return it as a response to the initial API call and the agent renders it as you can see below. Note that we’ve set up the agent to always include a link to the relevant articles so the customer can read up for more information and to generate trust. This is also super easy to set up as you can pass in metadata like URLs when you are loading data into your vector database.
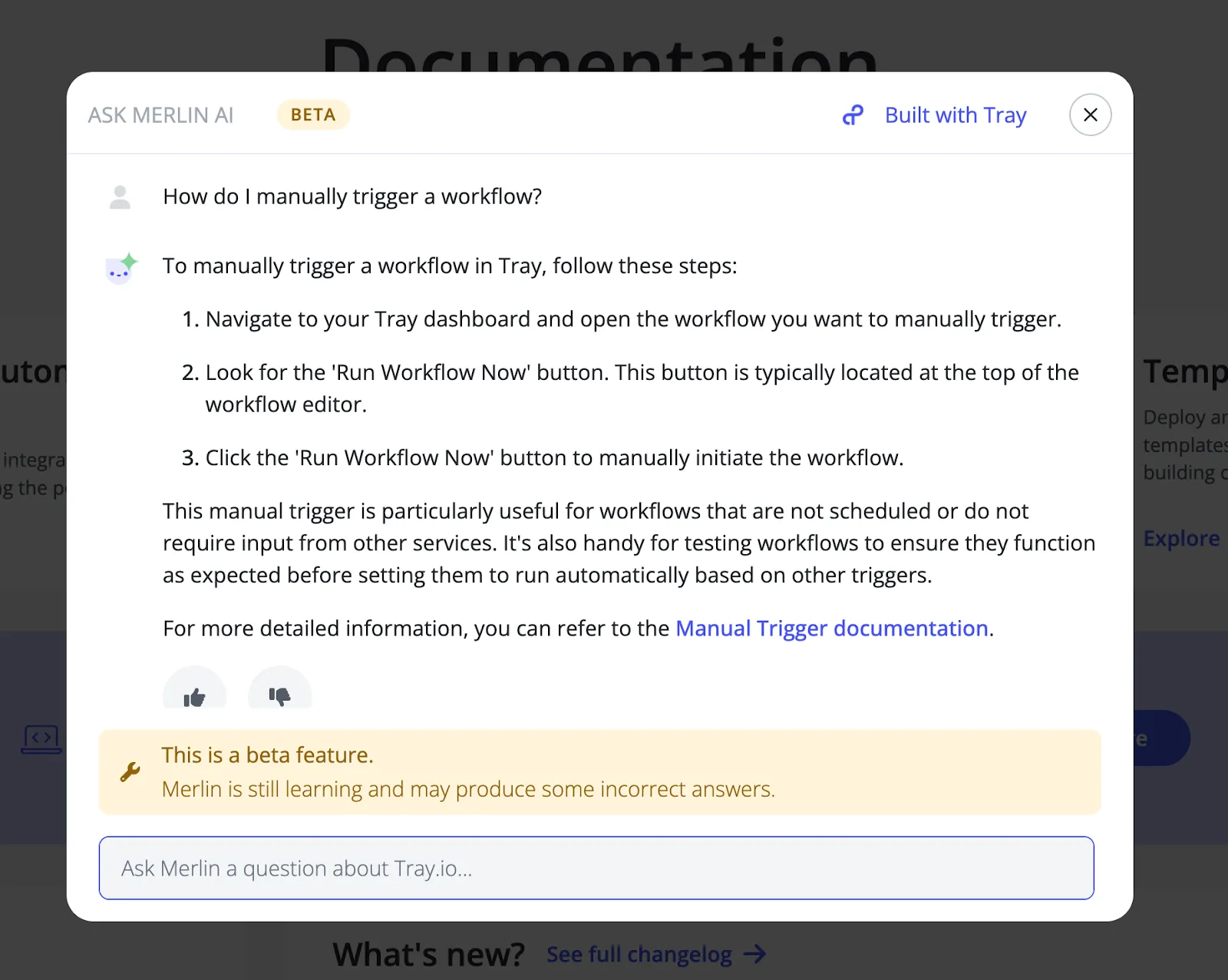
intelligent knowledge agent blog image 5
That’s how we built but why not go and try it out? Just “Ask Merlin” from the homepage of our knowledge base
What’s next
The agent is now in place and is making it super easy to navigate our documentation, but we’re not stopping there. As I covered earlier in the blog post, Tray makes it very easy to not only ingest data from pretty much any system but to also integrate the AI processes you build on Tray within your existing business processes. Here are just a few of the things we’re working on:
- Integrating the existing knowledge agent within our customer support workflow so that we can draft responses to support queries as they come in.
- Creating an internal version of the knowledge agent with information from support tickets, community questions, internal knowledge bases, and win/loss data to expand its capabilities beyond understanding and using Tray to become an essential member of the sales team that is capable of routing leads and suggesting actions as a deal develops.
- Ingesting all of the feedback we receive from our users to develop a new agent that can assess our roadmap and highlight any gaps.
Start building today
It’s time to stop experimenting with AI and start enriching your processes and making your teams more efficient. With Tray, you can get started right away and without having to hire a bunch of AI experts or massively expand your engineering team to build out complex pipelines while locking in with particular vendors. You can build a knowledge agent powered by a RAG pipeline to enhance your customer support team’s efficiency, as well as other dynamic AI processes that integrate seamlessly throughout your organization.
To fast-track your building journey, we even offer a ready-made template for building a RAG pipeline with GitHub, Pinecone and OpenAI that you can import right now.
One thing you can definitely be certain of is that your competitors are exploring options to enhance their business with AI. It’s not too late but if you’re starting from scratch or looking at expanding the expertise in your team then why not kick-start the process with Tray? With a complete set of integrations to the latest LLMs and AI infrastructure you can eliminate months of manual work whilst maintaining complete flexibility in your implementation. Try out the agent we have built here and then jump in and get an agent up and running with your data that you can integrate within your business processes in just a couple of weeks and save $100k+ this year.