
Cloud-based platforms are instrumental in making data-driven decisions across your organization, but they’re only as valuable as the data you store in them. And with a rising number of departments, use cases, and data sources, you can quickly become overwhelmed with requests for resource-draining custom integrations to pipe, manipulate, and analyze that data. Data analysts and IT frequently receive data-related requests, either for analytics reports or for support on extracting, transforming, or loading (ETL) data between different sources. This article will discuss how to use automation to easily tackle all those data requests within a single platform.
Whether it is sending data from your CRM to your data lake, or connecting a BI tool to your SQL server, using a modern iPaaS like Tray can significantly reduce the time it takes to launch custom integrations within your tech stack. Tray is an easy-to-use and low-code platform for automating and integrating complex business processes. The beauty of Tray is twofold: First, it empowers business users to build their own solutions using a drag-and-drop, low-code visual builder. Second, it features the flexibility and power to enable technical users to rapidly build integrations that are easier to maintain. In this post, we’ll show you how Tray can augment your data governance with AWS automations for analytics, storage, and even message queuing.
Three ways automation can augment data transfer and analytics
This post will focus on three sample use cases that automate mission-critical processes in data governance and storage. With each use case, we’ll highlight how you can use Tray to transform, store, and deliver data in a faster and more-scalable way, without having to worry about manual data management or building out or maintaining integrations.
- Data warehouses (such as AWS Redshift) - Automated data piping can slash custom integration development times while allowing you to perform ETL actions without restrictions for cleaner and more-accessible data to use for a variety of analytics.
- Object storage services (such as AWS S3) - Tray can facilitate automatic file transfers to S3 buckets for more-organized and accessible long-term storage.
- Message queuing services (such as AWS SQS) - Tray can combine multiple streams of data to work around API rate limits and queue high volumes of data into other systems.
Use case #1: Aggregate and prepare analytics data from multiple sources with data warehouse automation
Data warehouses (like Redshift) are highly scalable data repositories that store, segment, and access data to surface metrics and create reports. These systems are so robust that many teams use them to house data across their entire organization, including prospect behavior data, customer relationships data, and product usage data.
While custom integrations are a natural next step in ensuring these varying data sources are synchronized, they require expensive resources and can take significant time away from developers that could instead be invested in other areas. Tray, on the other hand, can empower you to complete the same integrations in significantly less time. Tray lets users visually integrate different services by dragging and dropping them into multi-step workflows, like this one:
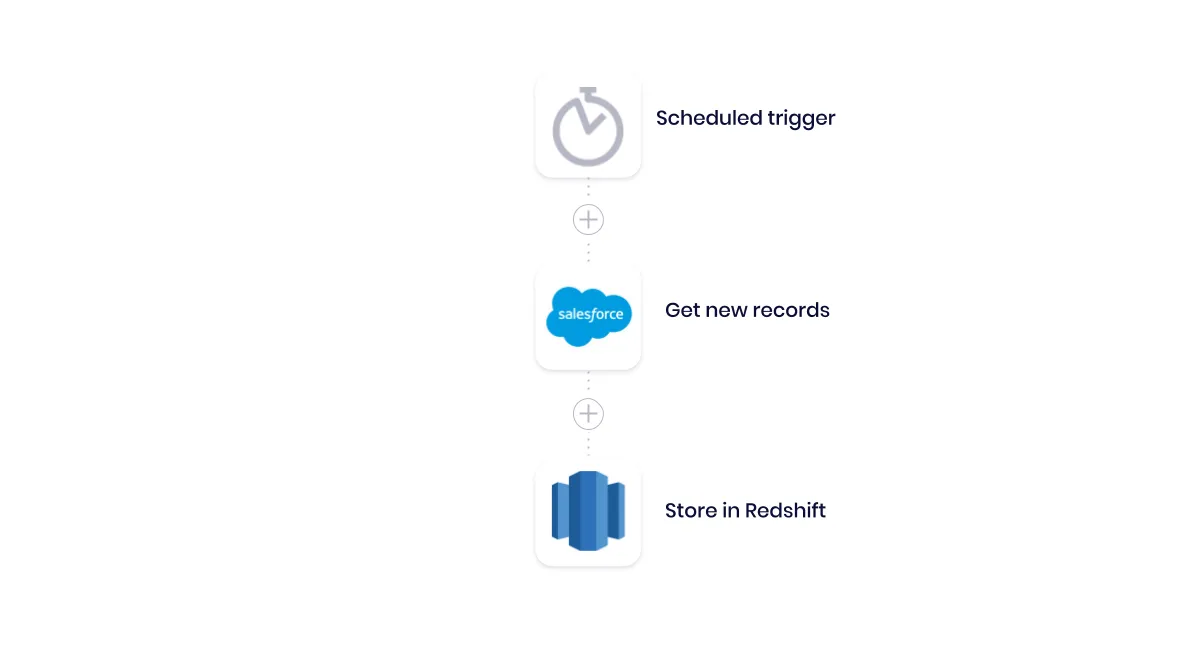
AWSAutomation 1.
In this workflow, we start with a scheduled trigger to ensure our workflow runs every day. Next, we call on our CRM, Salesforce, to get a list of records that we added in the previous period. Then, we sync those records with Redshift to refresh our dataset.
In addition to piping data into your data warehouse, Tray can help you pull data from it. Here’s another use case, which involves tagging prospects with activity data from our web chat tool:

AWSAutomation 2
Here, we pull data from Redshift and through our web chat service, Intercom, to tag prospects as ‘active’ or ‘inactive’. Then, we update our records in both our CRM and our data warehouse.
Tray also lets you weave custom logic, called helpers, between connectors, so you can aggregate and manipulate data for easier access and segmentation.
Use case #2: Store files and monitor performance with object storage automation
Amazon S3 (Simple Storage Service) is a popular option used by companies to host, store, and archive files on the web. One common use of this service is to store historical data in cheaper, infrequently-accessed archives that you can access at a later date (an approach often referred to as a data lake).
The following workflow uses S3 and Redshift (a data warehouse), to create an automated process for sending Google Analytics data to our long-term storage:

AWSAutomation 3
Our workflow first calls on Google Analytics to get a new list of website performance data (such as pageviews, clicks, conversions, and bounce rate) from a set period. Then, it stores our sheet in S3, which we can easily access at a later date via a PUT request.
We can apply this same process to virtually any use case related to adding, accessing, or managing files in your object storage service, ensuring a single comprehensive source of data without the painstaking process of developing dozens of one-off integrations.
Use case #3: Avoid rate limits/throttling with message queuing service automation
Message queuing services (like SQS) are helpful when passing data among services that might have rate limits. By queuing messaging data in deliberate sequences, you can ensure you don’t over-send messages that may end up being throttled by messaging or API limits.
And while some message queuing services like AWS SQS are easy to integrate with other services from the same publisher, they don’t always work well with other services. In such cases, your technical teams need to invest many hours into building and maintaining custom integrations. However, using Tray lets you string together different services in a single data queuing process. Here’s an example of a workflow we built to manage the testing (or launch) of a high-priority IT project for which receiving and logging new issues is crucial:
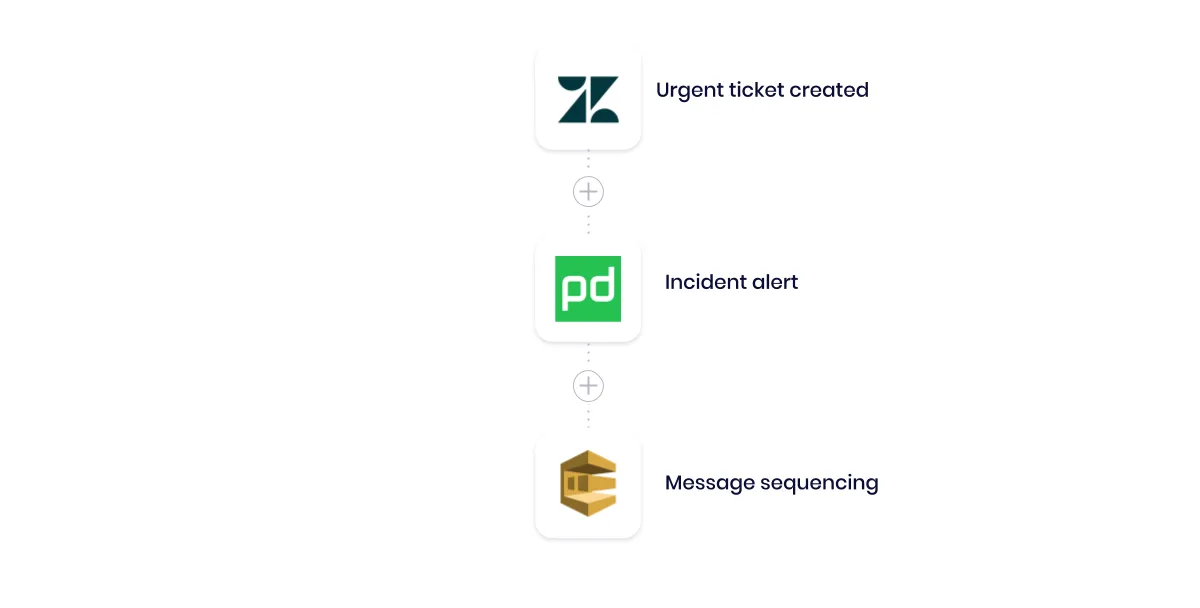
AWSAutomation 4
Our workflow calls on our helpdesk (Zendesk) to trigger whenever a support agent logs a new issue. The workflow then routes urgent tickets to our incident management software (PagerDuty), which sends SMS messages to on-duty field agents. The workflow then uses SQS to rate-limit messages to ensure that all messages get through, without potentially being throttled or flagged as spam by a mobile provider in case of volume spikes in reported issues.
Use automation to power data-driven insights across your organization
You should now have an idea of how a modern iPaaS like Tray can complement your existing cloud-based data tools to unlock and seamlessly transfer data from other services faster, cleaner, and more effectively.
Interested in seeing more ways Tray can integrate and automate your tech stack? Learn more here.