Data Storage
Store data and create local variables in Tray with the Data Storage core connector
The Data Storage connector
The Data Storage connector allows you to set and get arbitrary data, or perform more complex operations on lists and objects. It works using a key-value store, whereby key is the name of the field and value is the actual value of that piece of data. For example a piece of data might have a key of first_name and a value of Roger. This means that you can set any type of value you like, using a key to retrieve it. Data Storage can allow you to work with stored data and easily share it between multiple steps in your workflow.
Data being stored or retrieved by the data storage connector is visible in the Tray logs. Therefore the data storage connector should not be used for storing sensitive information such as authentication credentials.
Auth credentials should always be stored in actual authentications, which can then be retrieved using $.auth environment variables, whereby the credentials are always obscured in the logs.
When working with stored data, you also have the option to set the scope:
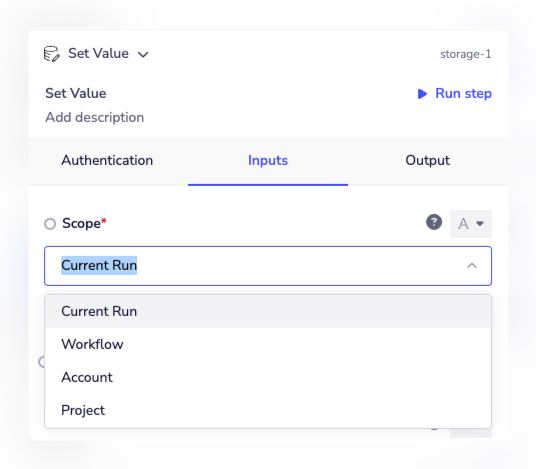
- Current Run means that the data will not be available the next time a workflow is run. For example you may wish to store a count of records/accounts returned while looping through a list of results.
- Workflow means that the data will be saved for all runs of the workflow. For example you may wish to record the cumulative number of users who have submitted a form using your workflow.
- Project means that the data will be saved for all runs of the project. You can use this to pass data across workflows within a single project. This scope is not available within solutions or solutions instances.
- Account means that the data is saved and can be used by other workflows within the same Workspace. An example of this can be seen in our Workflow threads tutorial. Please also be sure to see the below note on clearing account level data. It is advisable to use the narrowest scope necessary for your use case - this helps prevent any unwanted overwriting of data between different executions or workflows.
Data retention policies and storage limits
To allow for delays in workflow completion, data stored under Current Run scope is stored for 30 days from execution. Data stored under Workflow is available only inside that workflow and will be deleted upon deletion of the workflow. Data stored under Project is available only inside that project and will be deleted upon deletion of the project. Data stored under Account scope is available across all workflows of the workspace (where this workflow is present). It will be deleted upon deletion of the workspace. There is no limit to overall data storage. However the limit under a single key is 400KB. Objects up to 32 levels of depth can be stored. If you need more deeply-nested objects when using the 'Set value' operation, you can use the 'Force store in older format' option in advanced properties. Again, please see the below note on clearing account level data to make sure that your storage under a single key does not exceed its limit.
EMBEDDED NOTES:
- The account scope can be used to share data between the solution instances of an end user if needed.
- If you want to share data between workflows of solution instance, you will need one workflow that will act as Data storage API for your solution instance. For more details around setup, refer this blog here
Setting and getting data with data storage
Setting and getting single keys
When you need to store single keys you can use the data storage 'Set value' and 'Get value' operations.
In this example we're going to show you a simple use case where support tickets are coming in to a webhook-triggered workflow, and we are wanting to assign a priority to them before processing:
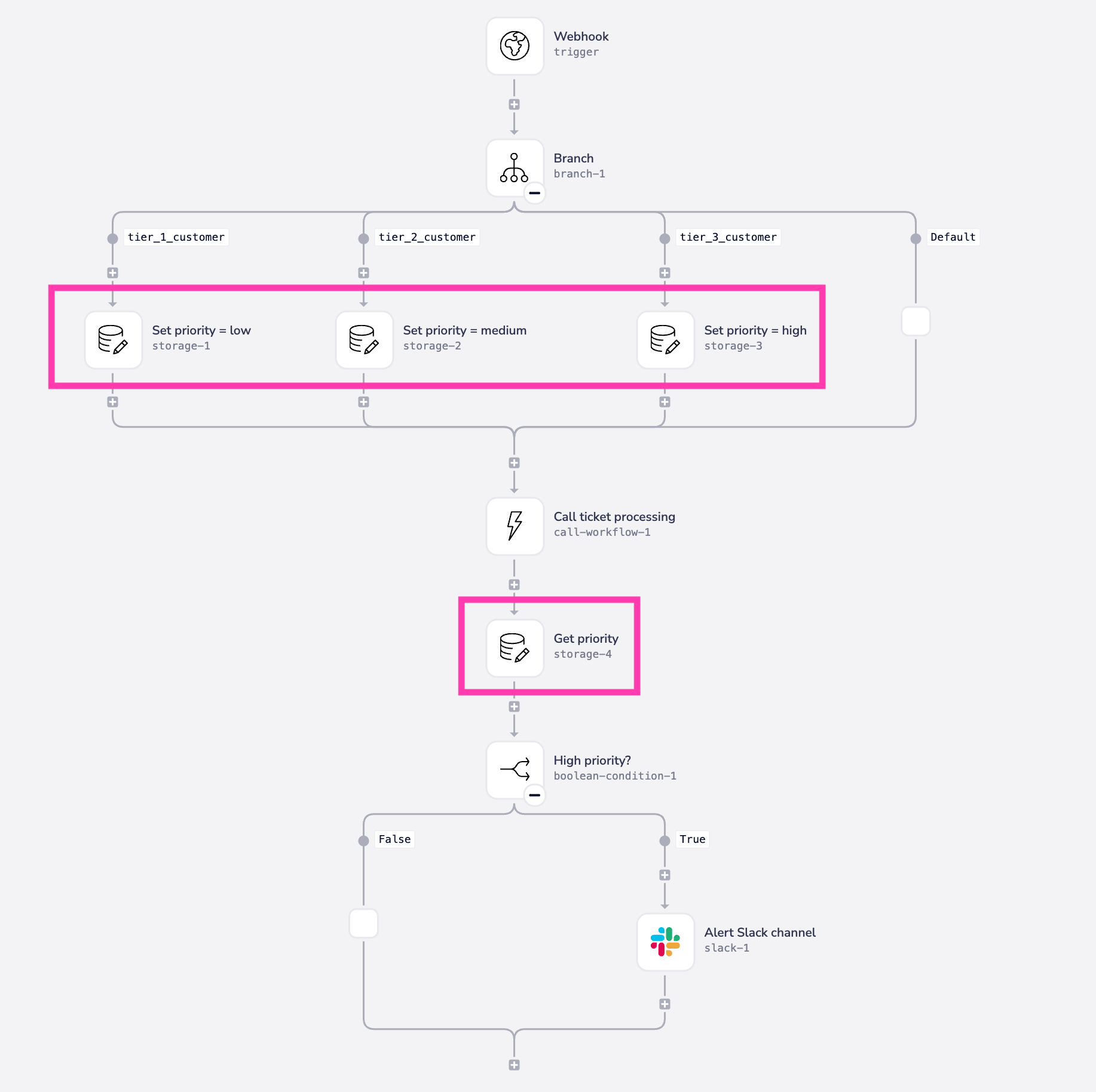 Here we are:
Here we are:
- Using the branch connector to check a certain value (customer tier in this case) in the webhook payload
- Depending on the customer tier we are then setting the value of the 'priority' key as 'low', 'medium' or 'high' on the appropriate branch:
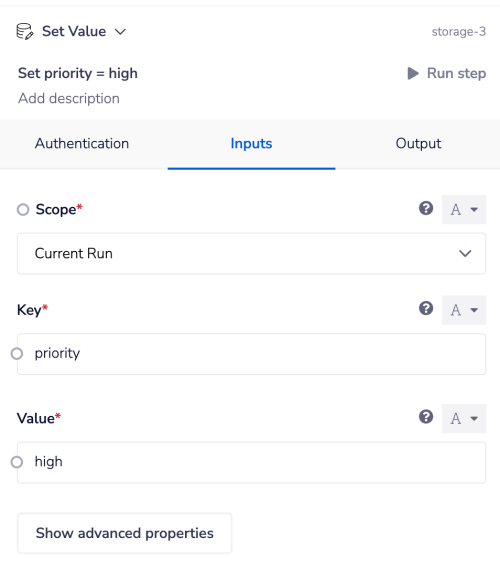
- After sending all tickets to the 'ticket processing' workflow we are then making a final check if the priority has been set as 'high'.
We do this by using the 'Get value' operation:
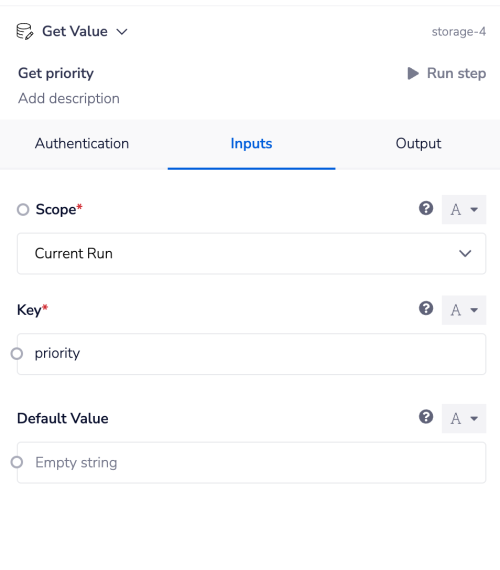 Followed by a boolean check to see if the retrieved value is 'high' - in which case send a Slack alert message.
This example illustrates some key points about setting and getting values:
Followed by a boolean check to see if the retrieved value is 'high' - in which case send a Slack alert message.
This example illustrates some key points about setting and getting values:
- When you use 'get value' the value always depends on what it was last set to
- Using 'set value' you can change the value of a key multiple times within a workflow
- Using conditionals (branch and boolean) is important in effective use of getting and setting
Setting and getting lists / arrays with data storage
When you need to store lists / arrays of data you can use the 'Append to list' operation in conjunction with the 'get value' operation.
The following example shows this being used in a RAG pipeline project:
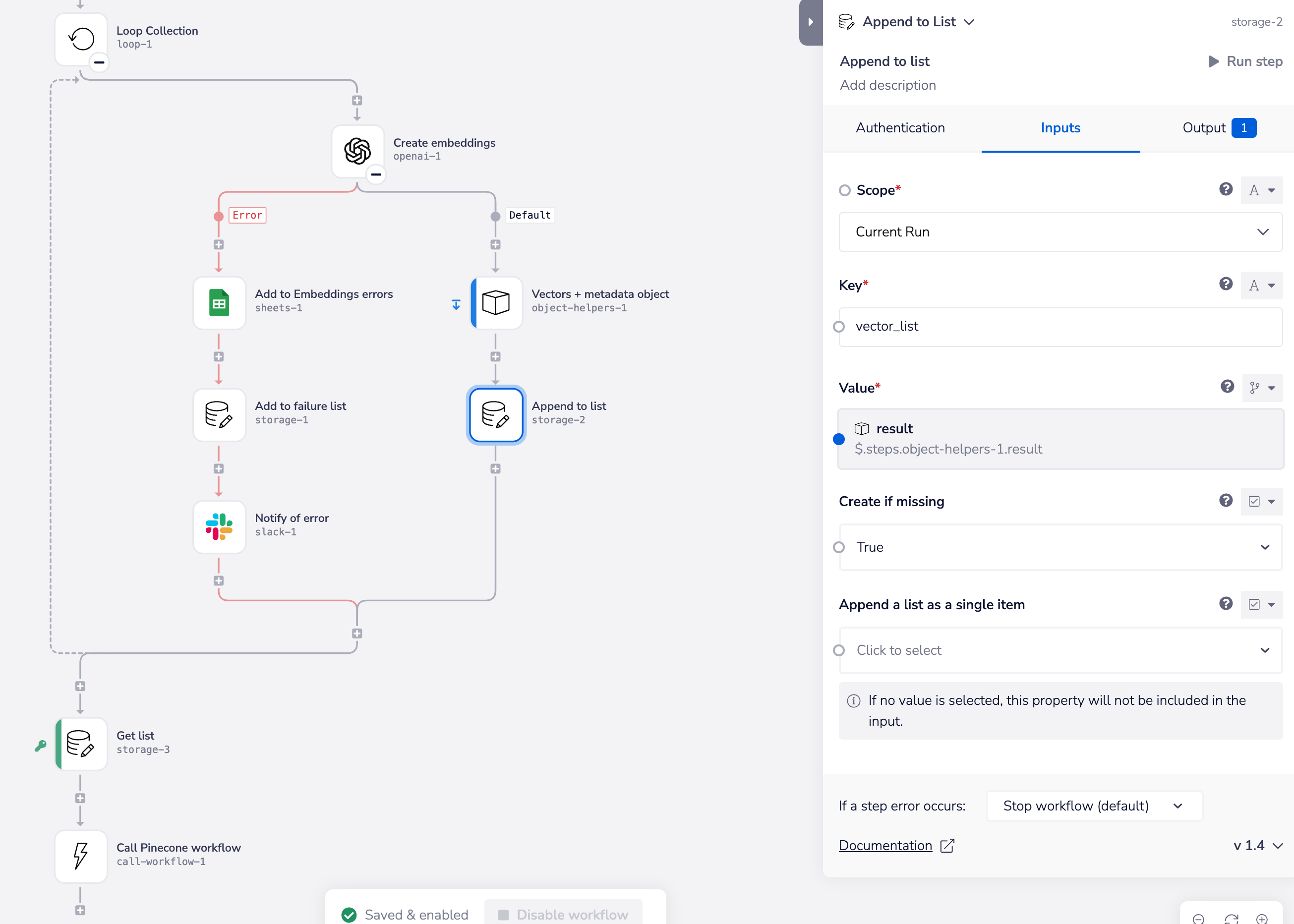 In this case we have:
In this case we have:
- A list of source information where we want to modify / enrich each item and add to a new list in data storage (in this case we have used an LLM to create vector embeddings for each piece of content)
- With the Object Helpers 'Add key / value pairs' operation, for each item we have combined the original data / metadata into a single object along with the additional data (vectors in this case)
- We then use the data storage 'Append to list' operation as per the above workflow screenshot to add each object to an arbitrary key - called 'vector_list' in this case (making sure to set 'Create if missing' to True)
- After the loop we then use the data storage 'get value' operation to get the complete list
- It is then very common to send retrieved lists to a callable workflow for further processing. In this case we are sending it to a workflow where it will be uploaded to a vector database. This ensures that batches of retrieved data are processed in parallel and thus minimizes execution time
Notes on setting and getting
Using the Default Value
When using the Data storage 'get value' operation, if the given key is not found then the default value will be returned - which can be set to anything. This is really useful for initialising new lists, strings, or counters that you plan to add things to. For example, now the first Get call for a new key can return an empty list, empty string, or 0, rather than null. When working with similar data, consider using a list instead of multiple, single items under different keys.
Possible Issues
Be aware of possible issues when using Workflow, Project, and Account scopes:
- Data could become inconsistent if multiple executions are concurrently loading, modifying and then saving a value under the same key
Managing data storage limits
As mentioned above, the data storage limit under a single key is 400KB. If this limit is exceeded, your workflow will return a Tray system error with the message 'Data under this key has exceeded the maximum allowed size' When using the 'Append to list' operation to create lists which may contain thousands of records and / or each object in a list contains a lot of data, you may find that you exceed this limit. A common use case where this might happen is when you are enriching / transforming items contained in lists of data, whereby you are:
- Retrieving an array of data from a particular source
- Looping through each item and creating a new object with the additional / transformed data
- Using 'Append to list' to add each object to a new list to be processed to a final destination
Simple method for predictable datasets
This approach works well for small-scale implementations and when the size of each item in a list is consistent (i.e. you are carrying out the same transformation or adding the same amount of data to each object)
One simple method of dealing with this is to first of all run tests which will tell you how many items are in the list when it starts to exceed the limit, then create batches of items and send them to a callable workflow for processing.
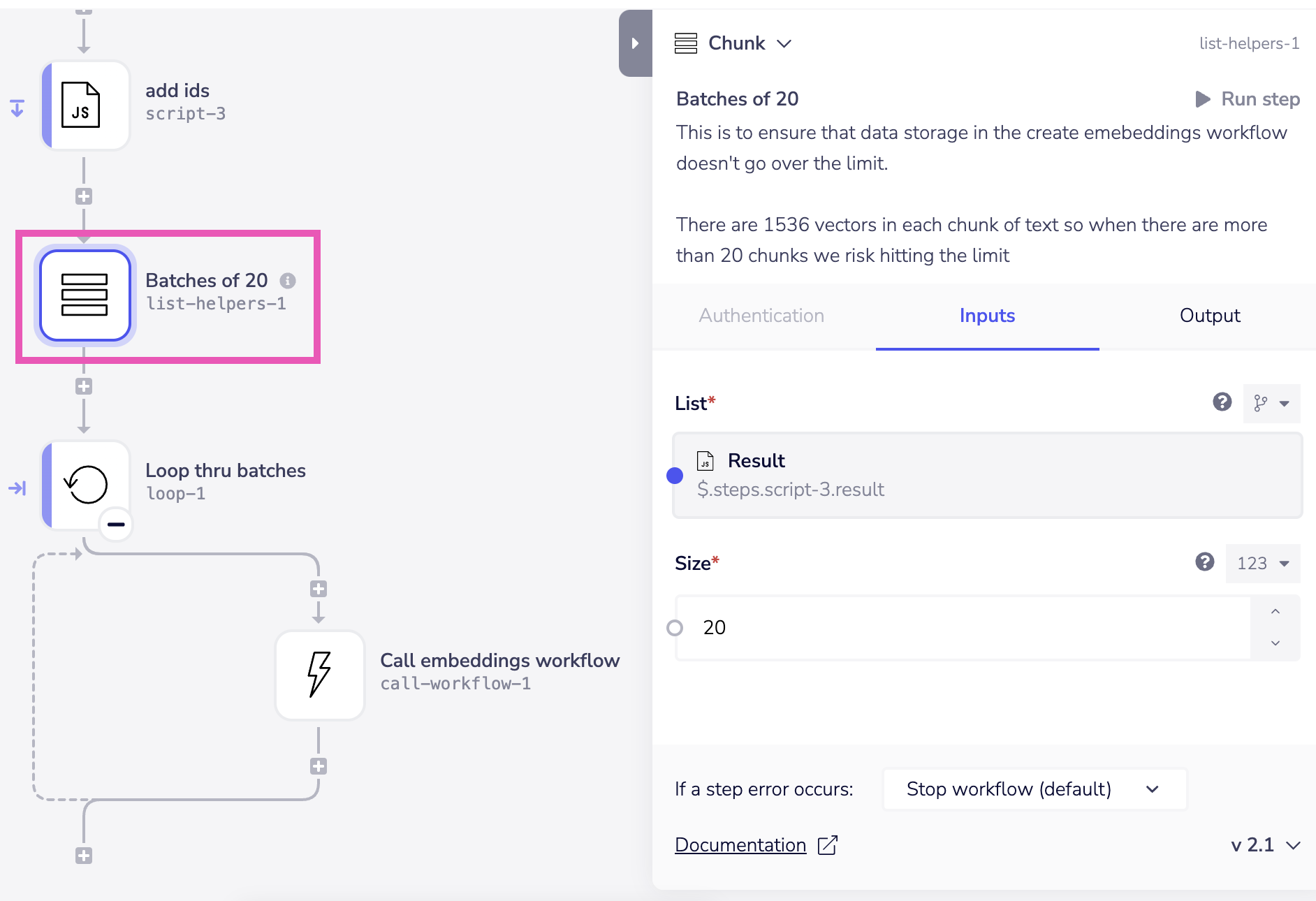
With the RAG pipeline example above, we found that the workflow which creates vector embeddings and stores objects in a list was hitting the limit with about 30 objects, because there are 1536 vectors in each object.
To solve this we used the List Helpers 'Chunk' operation to chunk the list in batches of 20 before we sent it to the workflow which creates the embeddings for each item in the list:
Dynamic method for variable datasets
This method works when you are enriching / transforming each object in a list and the amount of data added can vary significantly, therefore predicting how many items can be added to the list is risky
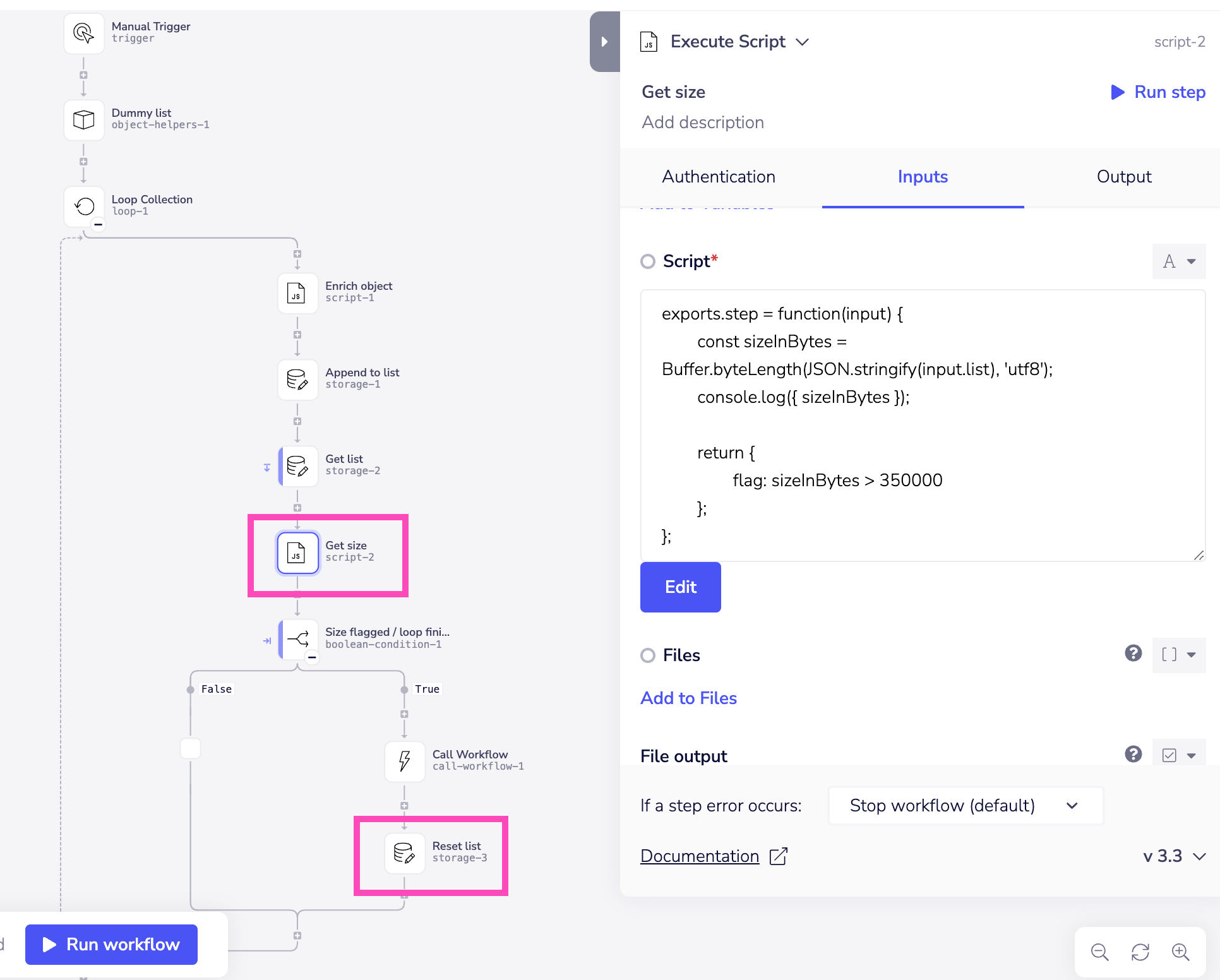
If the size of each item varies significantly then you will need to implement a more dynamic checking mechanism. In the example below, we are:
- Looping through a list, enriching each object and using 'append to list' to create a new list.
- In each run of the loop we are using a script to check the size of the list.
- We then use a boolean to check if the script has flagged that the list is reaching the limit (or if the loop 'last_run' value is true).
- If so then we send the list to a callable workflow for processing and, crucially, use the Data Storage 'set value' operation to reset the list as an empty array.
The loop will then continue creating a new list with the next item from the array:
Clearing Account level data
When using the Data storage connector, often you will need to clear account level data - particularly when building and testing workflows which might error out and leave values and lists set in a way which means you can't run your workflows again.
It is good practice to finish workflows with data storage connector steps which reset the data.
You can also consider making a manually triggered workflow specifically to clear account-level data so you can retest your workflows:
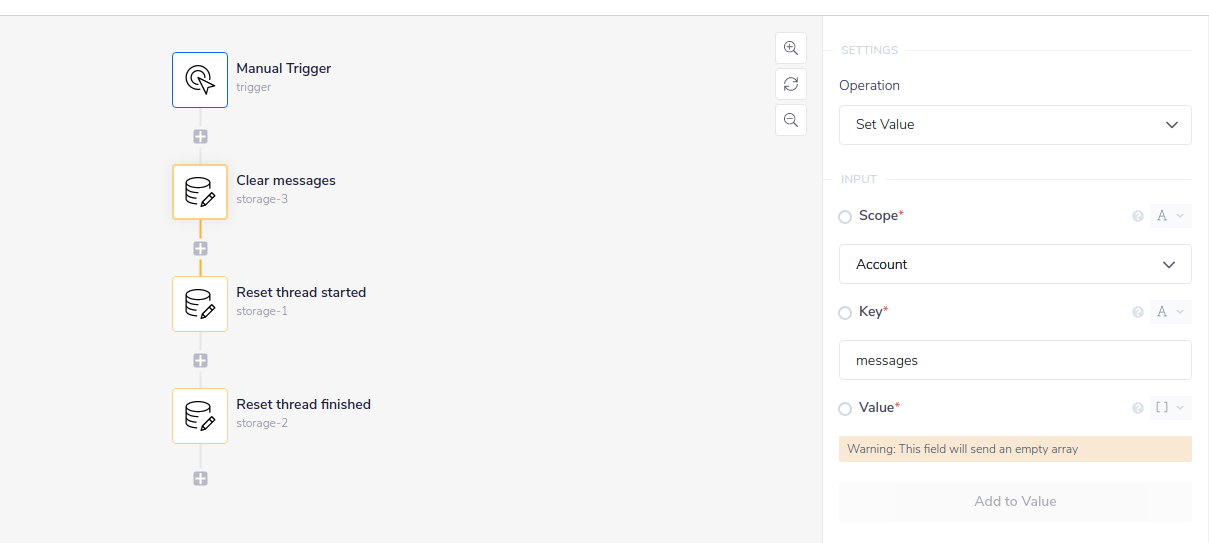 When doing this be sure to set the data to the correct data type according to how you use it - e.g. an empty array as in the above example, or a number 0, or an empty string, etc.
When doing this be sure to set the data to the correct data type according to how you use it - e.g. an empty array as in the above example, or a number 0, or an empty string, etc.
Clearing All Account level data
IMPORTANT!: It is extremely risky to clear your account level data en mass. It will effect all the people in your workspace / organisation. Please make sure you are completely certain of what you intend to clear and who it will effect before proceeding.
We highly recommend you use the above method outlined if you intend to clear your account level data. It is safer as it is more specific.
If however you do require a large scale clear out it is possible using the following method.
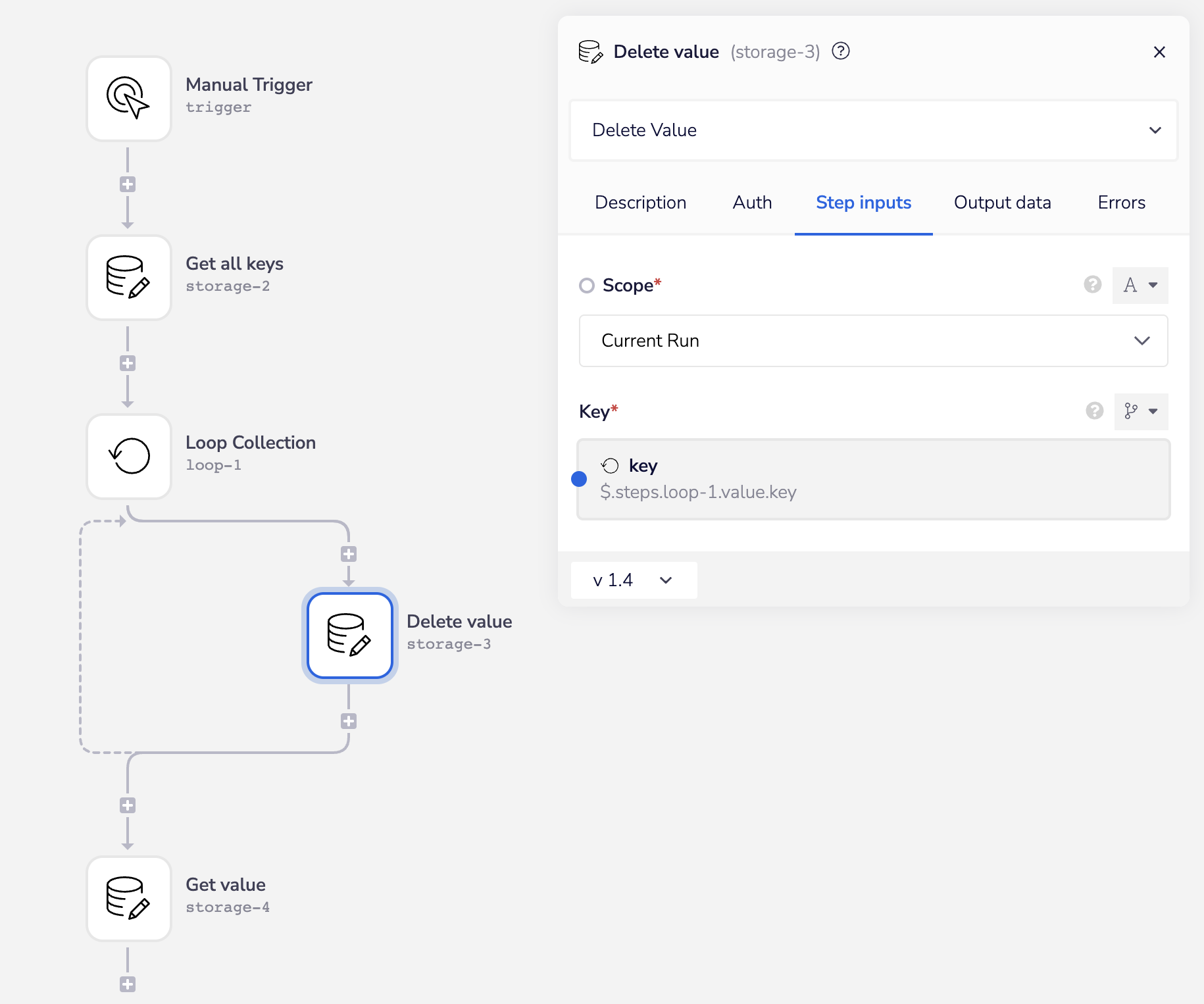
Set the first Data storage connector to Get all keys. Loop your results using the Loop list operation and within this loop connector add another Data storage step. Set the operation to Delete value.
Add some checks to be sure the results are as expected. For example below we have added a Get value step which confirms the result is now null. Another option might be to add a Boolean check within the loop to confirm the iterated key is as expected.
The Atomic Increment operation
The Data storage connector's 'Atomic Increment' operation is basically a counter which increases by one every time it is hit. This can be used in loops so that you can count every time an action is taken. Please see the tutorial on Workflow Threads for an example use case.
Important Note on Advanced Operations
Be aware that the Add to Collection and Shift Collection operations should only be used as a last resort, as they have reliability and performance limitations if used in Workflow or Account scope. They can be used to implement a queue, but if possible, use the AWS SQS connector instead.