Databricks
Databricks is a cloud-based data engineering platform for processing and transforming massive data quantities with unified analytics and machine learning.
Overview
Databricks is an industry-leading, cloud-based data engineering tool used for processing and transforming massive quantities of data and exploring the data through machine learning models.
API INFO: The Base URL used for the Databricks connector is <databricks_instance>/api. More information can be found on their main API documentation (v1.2 and 2.0) site.
Authentication
Within the workflow builder, highlight the Databricks connector.
In the Databricks connector properties panel to the right of the builder, click on the Authenticate tab and the 'Add new authentication' button.
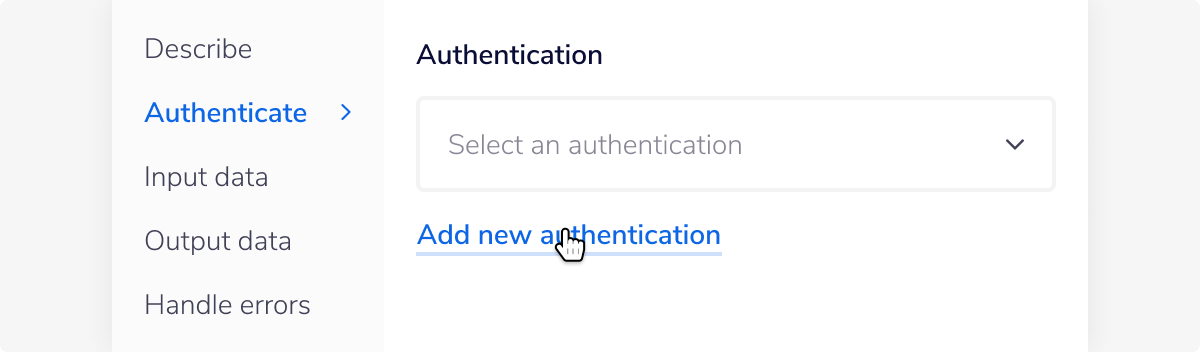 This will result in a Tray.io authentication pop-up model. The first page will ask you to name your authentication and select the type of authentication you wish to create ('Personal' or 'Organisational').
The next page asks you for your 'Databricks instance' and 'Personal access token'.
This will result in a Tray.io authentication pop-up model. The first page will ask you to name your authentication and select the type of authentication you wish to create ('Personal' or 'Organisational').
The next page asks you for your 'Databricks instance' and 'Personal access token'.
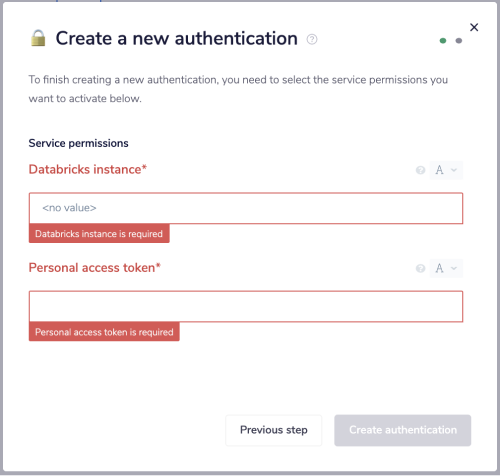 In order to get these fields, head to the databricks dashboard. The link for your deployment is the databricks instance you should use. Remove the slash ('/') at the end before adding it.
In order to get these fields, head to the databricks dashboard. The link for your deployment is the databricks instance you should use. Remove the slash ('/') at the end before adding it.
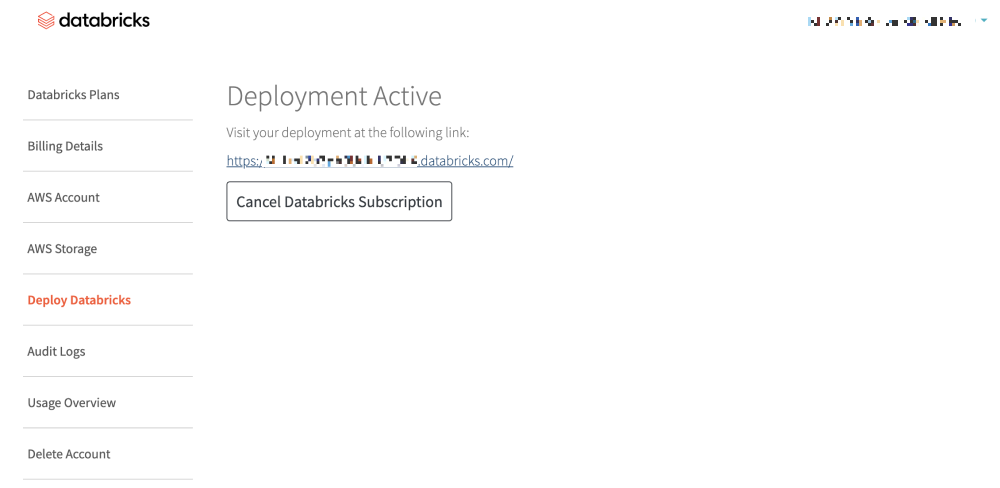 To get the access token, visit your deployment and then click on the user icon available on the top right corner.
To get the access token, visit your deployment and then click on the user icon available on the top right corner.
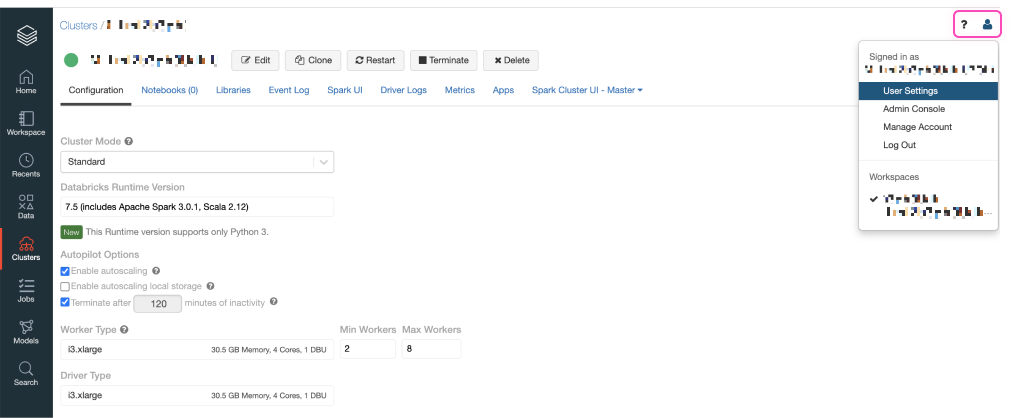 Doing so, will open the User Settings page. On this page select the 'Access Tokens' tab and click the 'Generate New Token' button.
Doing so, will open the User Settings page. On this page select the 'Access Tokens' tab and click the 'Generate New Token' button.
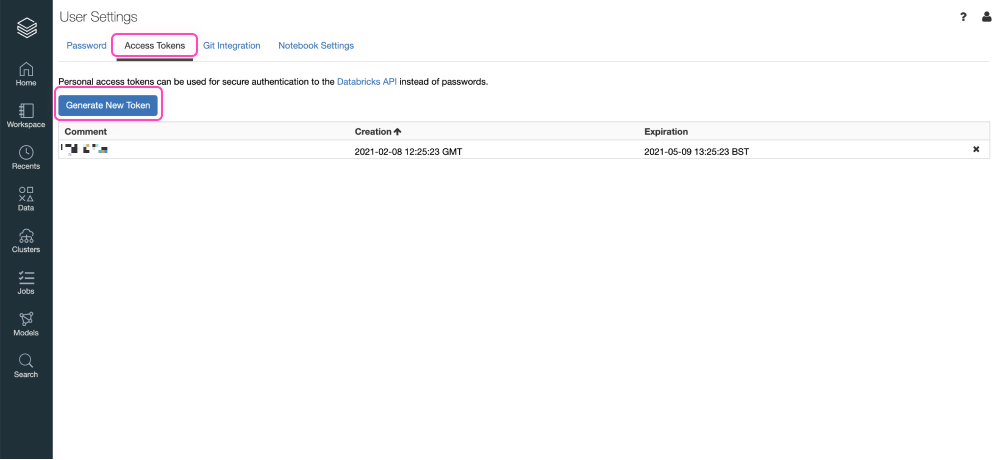 It will generate an access token, copy and paste the token on your Tray.io authentication modal.
It will generate an access token, copy and paste the token on your Tray.io authentication modal.
PLEASE NOTE: Make sure to copy the token when is gets generated. You won't be able to view the tokenagain.
Once you have added these fields to your Tray.io authentication popup window, click the 'Create authentication' button. Go back to your settings authentication field (within the workflow builder properties panel), and select the recently added authentication from the dropdown options now available. Your connector authentication setup should now be complete.
Using the Raw HTTP Request ('Universal Operation')
As of version 1.0, you can effectively create your own operations.
This is a very powerful feature which you can put to use when there is an endpoint in Databricks which is not used by any of our operations.
To use this you will first of all need to research the endpoint in the Databricks API documentation v1.2 or v2.0, to find the exact format that Databricks will be expecting the endpoint to be passed in.
Note that you will only need to add the suffix to the endpoint, as the base URL will be automatically set (the base URL is picked up from the value you entered when you created your authentication).
The base URL for Dabaricks is: <databricks_instance>/api
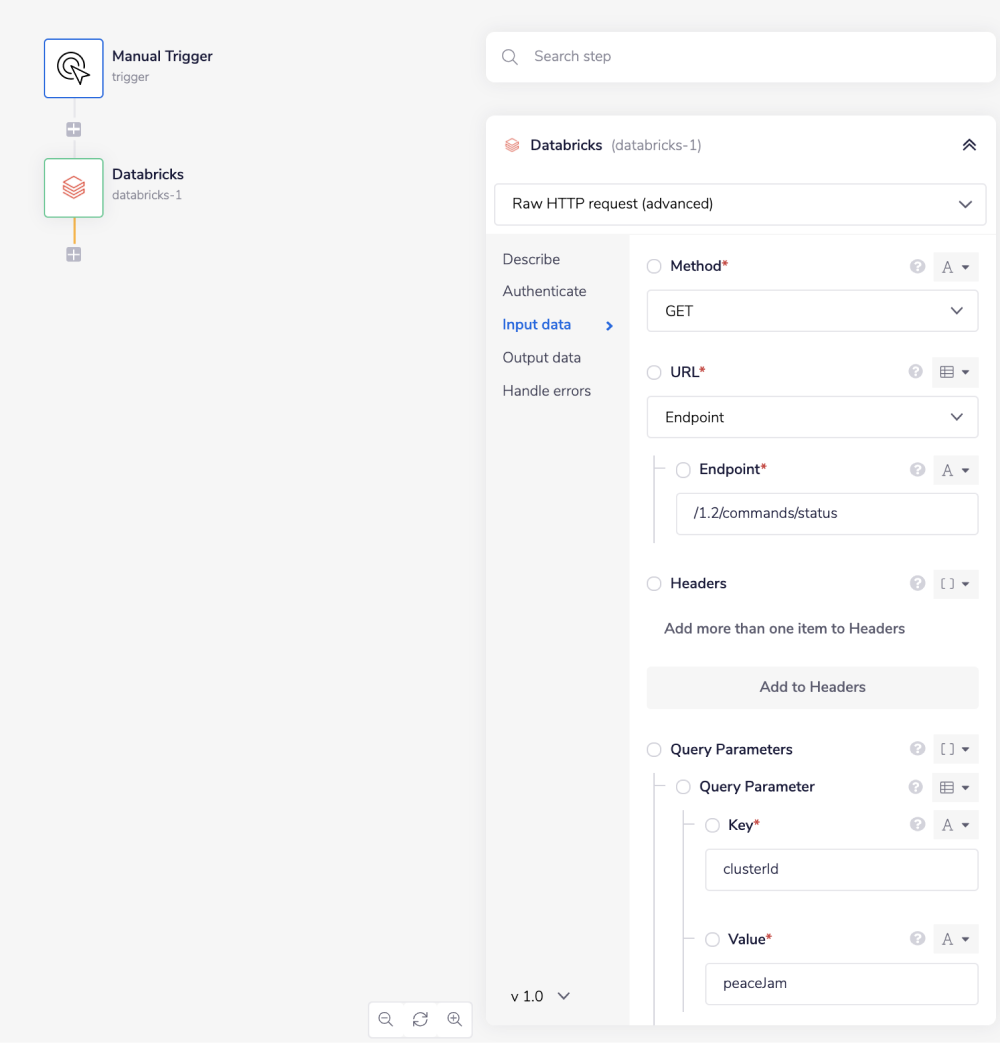
For example, say that the 'Get command status' operation did not exist in our Databricks connector, and you wanted to use this endpoint. You would use the Databricks API docs to find the relevant endpoint - which in this case is a GET request called: /1.2/commands/status.
More details about this endpoint can be found here.
 As you can see there is also the option to include a query parameter, should you wish to do so. So if you know what your method, endpoint and details of your query parameters are, you can get the command status information with the following settings:
Method:
As you can see there is also the option to include a query parameter, should you wish to do so. So if you know what your method, endpoint and details of your query parameters are, you can get the command status information with the following settings:
Method: GET
Endpoint: /1.2/commands/status
Query Parameter: Key: clusterId Value: peaceJam Key: contextId Value: 5456852751451433082 Key: commandId Value: 5220029674192230006
Body Type : None
Final outcome being: https://databricks_instance/api/1.2/commands/status?clusterId=peaceJam&contextId=5456852751451433082&commandId=5220029674192230006
Example Usage
TRAY POTENTIAL: Tray.io is extremely flexible. By design there is no fixed way of working with it - you can pull whatever data you need from other services and work with it using our core and helper connectors. This demo which follows shows only one possible way of working with Tray.io and the Databricks connector. Once you've finished working through this example please see our Introduction to working with data and jsonpaths page and Data Guide for more details.
Below is an example of a way in which you could potentially use the Databricks connector to upload and run a Spark jar. The steps will be as follows:
- Setup using a manual trigger and list all the Spark clusters.
- Loop through the received collection of clusters.
- Upload your local JAR and install it to each cluster.
- Create an execution context for the given programming language.
- Execute a command that uses your JAR.
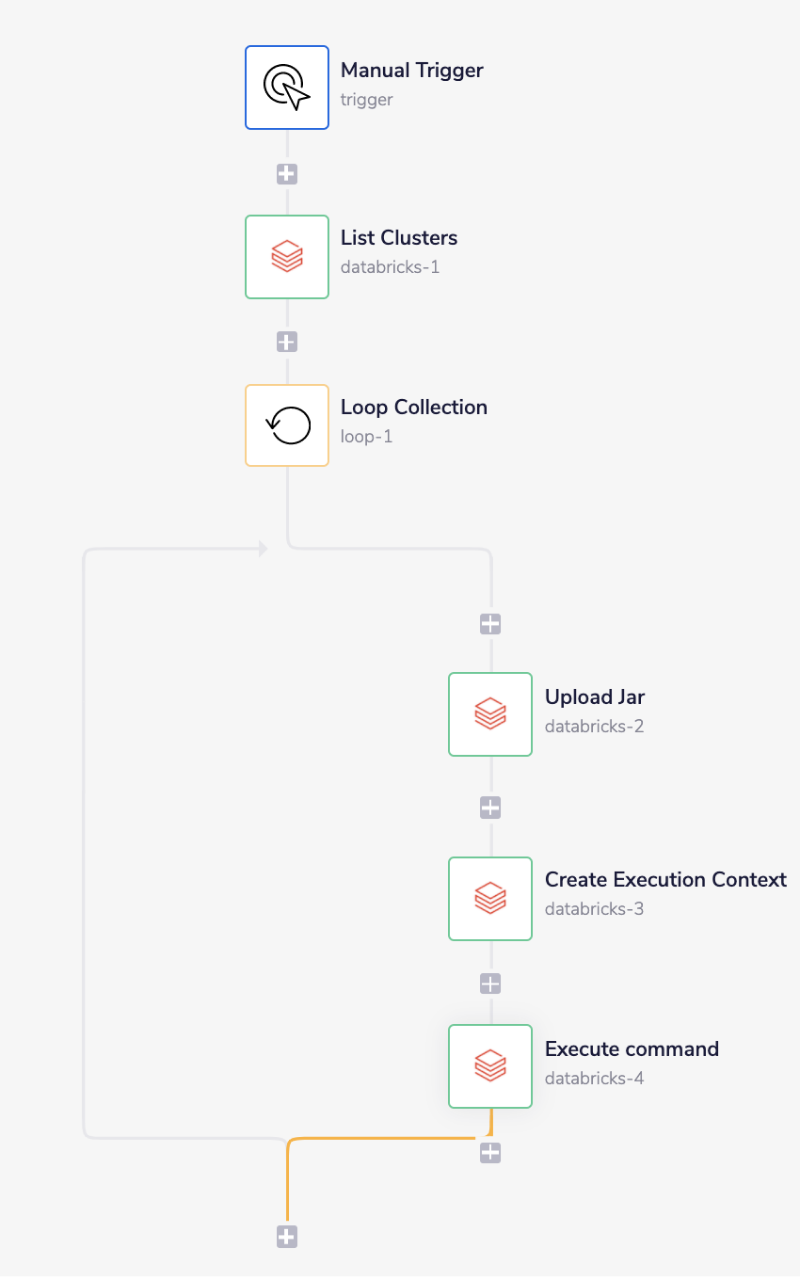
1 - Setup Trigger & List Clusters
Select the manual trigger from the trigger options available. From the connectors panel on the left, add a Databricks connector to your workflow. Set the operation to 'List clusters'.
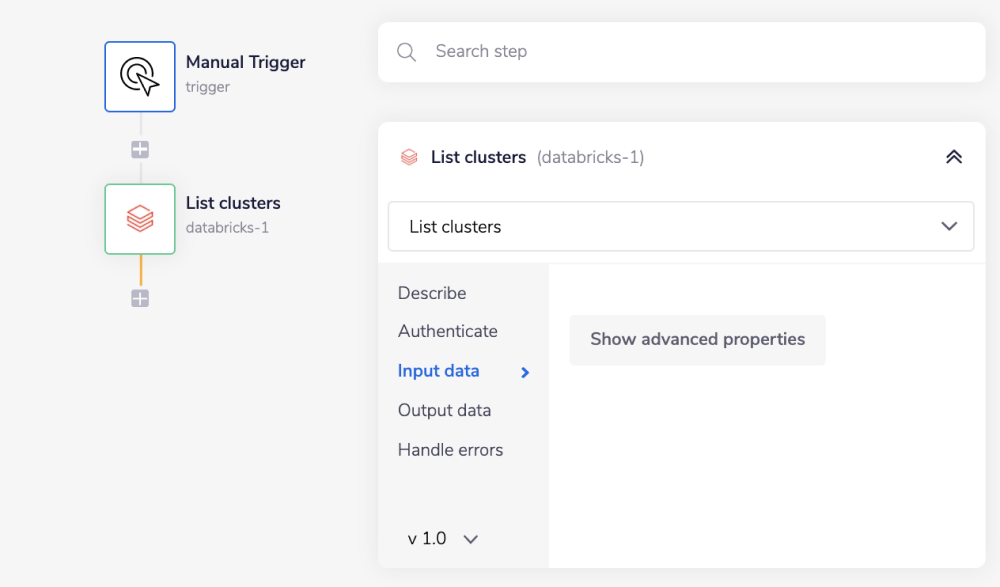 Feel free to re-name your steps as you go along to make things clearer for yourself and other users. The operation names themselves often suffice.
This step will return information about all pinned clusters, including the cluster ID, which we will use later.
Feel free to re-name your steps as you go along to make things clearer for yourself and other users. The operation names themselves often suffice.
This step will return information about all pinned clusters, including the cluster ID, which we will use later.
2 - Loop Collection & Upload JAR
Next, search for the Loop collection connector within your connector panel, and drag it into your workflow as your next step. Set your operations to 'Loop list'.
The Loop Collection connector allows you to iterate through a list of results. In this example, we will use it to iterate through the list of clusters received in the previous 'List Clusters' step.
In order to specify the list you want to loop through, start by using the list mapping icon (found next to the list input field, within the properties panel) to generate the connector-snake.
While hovering over the 'List Clusters' step (with the tail end of the connector-snake), select clusters from the list of output properties displayed. This will auto-populate a jsonpath within your list input field and update the type selector to jsonpath.
For more clarification on the pathways, you have available, open the Debug panel to view your step's Input and Output.
JSONPATHS: For more information on what jsonpaths are and how to use jsonpaths with Tray, please see our pages on Basic data concepts and Mapping data between steps
**CONNECTOR-SNAKE: **The simplest and easiest way to generate your jsonpaths is to use our feature called the Connector-snake. Please see the main page for more details.
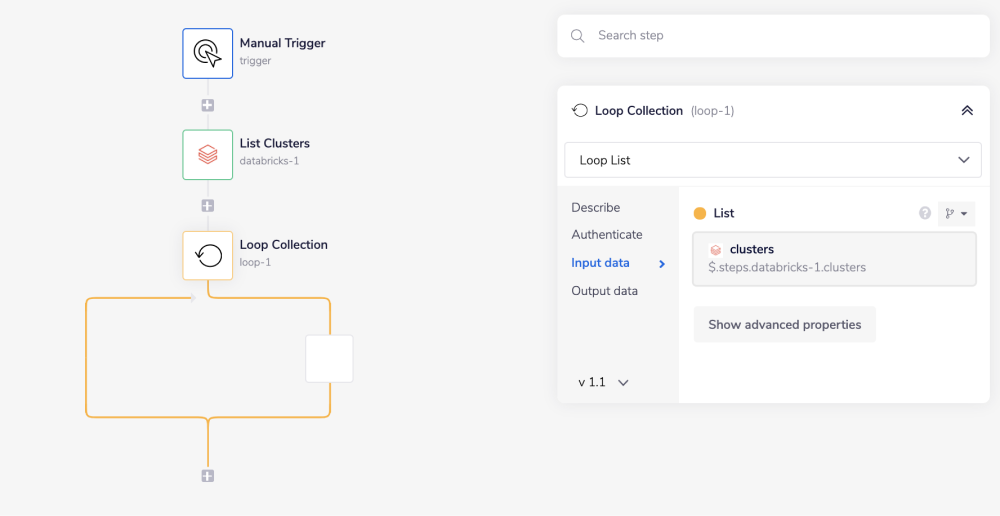 Once done, it will enable you to loop through the results of the previous step to get the information of each cluster.
The next step is to drag a Databricks connector inside of the 'Loop Collection' step itself. Then set the operation to 'Install libraries'.
As you can see, the 'Cluster ID' and 'Libraries' fields are required.
Once again, use the connector snake to hover over the 'Loop Collection' step (with the tail end of the connector-snake) and select cluster_id from the list of output properties displayed.
Click on 'Add to Libraries' to add the library you would like to upload. Select the library type as 'Jar' from the dropdown options available. In the 'Jar' field add the URI of the jar you would like to install.
At this stage, if the workflow doesn’t work as desired, then click on the ‘Debug’ tab to inspect your logs and see if you can find what the problem is.
Once done, it will enable you to loop through the results of the previous step to get the information of each cluster.
The next step is to drag a Databricks connector inside of the 'Loop Collection' step itself. Then set the operation to 'Install libraries'.
As you can see, the 'Cluster ID' and 'Libraries' fields are required.
Once again, use the connector snake to hover over the 'Loop Collection' step (with the tail end of the connector-snake) and select cluster_id from the list of output properties displayed.
Click on 'Add to Libraries' to add the library you would like to upload. Select the library type as 'Jar' from the dropdown options available. In the 'Jar' field add the URI of the jar you would like to install.
At this stage, if the workflow doesn’t work as desired, then click on the ‘Debug’ tab to inspect your logs and see if you can find what the problem is.
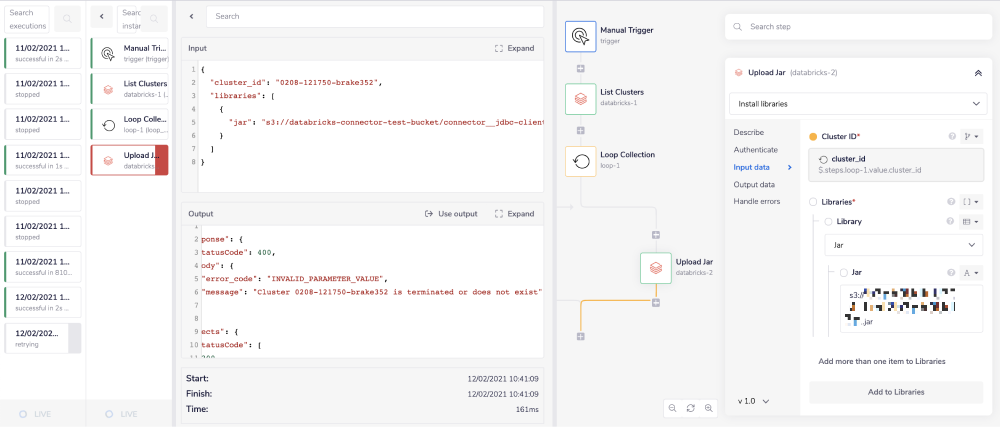
USER TIP: Make sure the clusters you are uploading your Jar to are running. You can checkthis by going to the 'clusters' section in your databricks account and checking the event log isshowing a status of 'DRIVER_HEALTHY'. If this is not the case and your cluster is terminated,click the 'start' button.
This will upload your jar library to every cluster so that you can then use commands from the jar.
3 - Create Execution Context & Execute Command
Now that you've uploaded your jar library, create an execution context by dragging another Databricks connector onto your workflow.
This time, set the operation to 'Create execution context'. You'll need to provide the 'Language' and 'Cluster ID' as input.
The language will be the programming language you defined when you created the clusters, in this case, scala. Set the jsonpath for the cluster ID by dragging the connector snake once again to the 'Loop Collection' step and selecting 'cluster_id'.The jsonpath should appear similar to $.steps.loop-1.value.cluster_id.
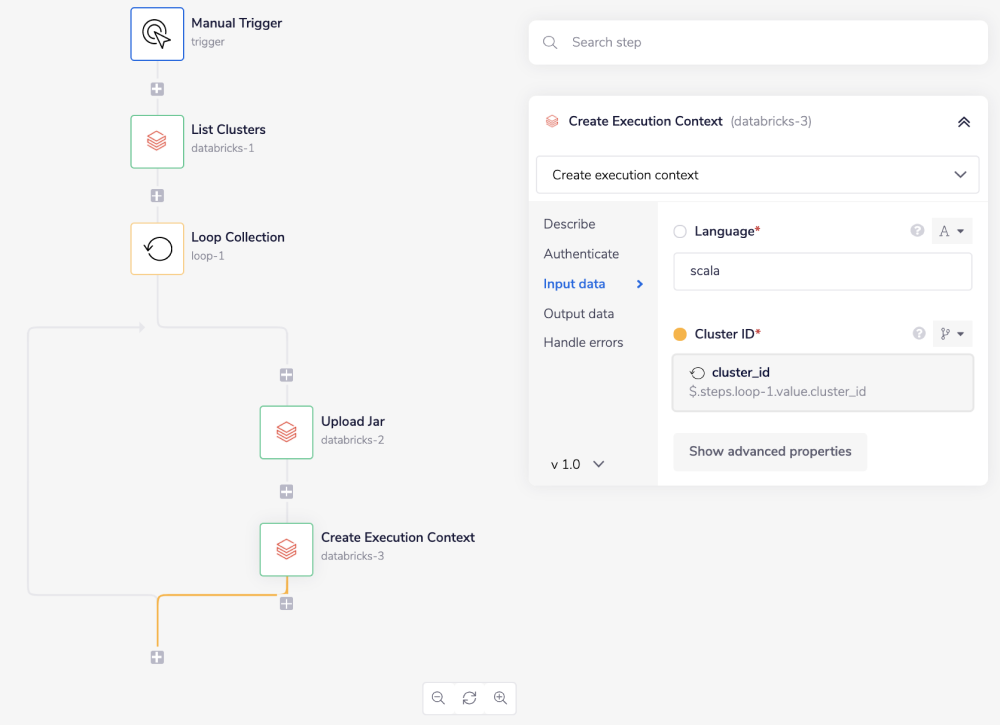 This will create an execution context in each of your clusters.
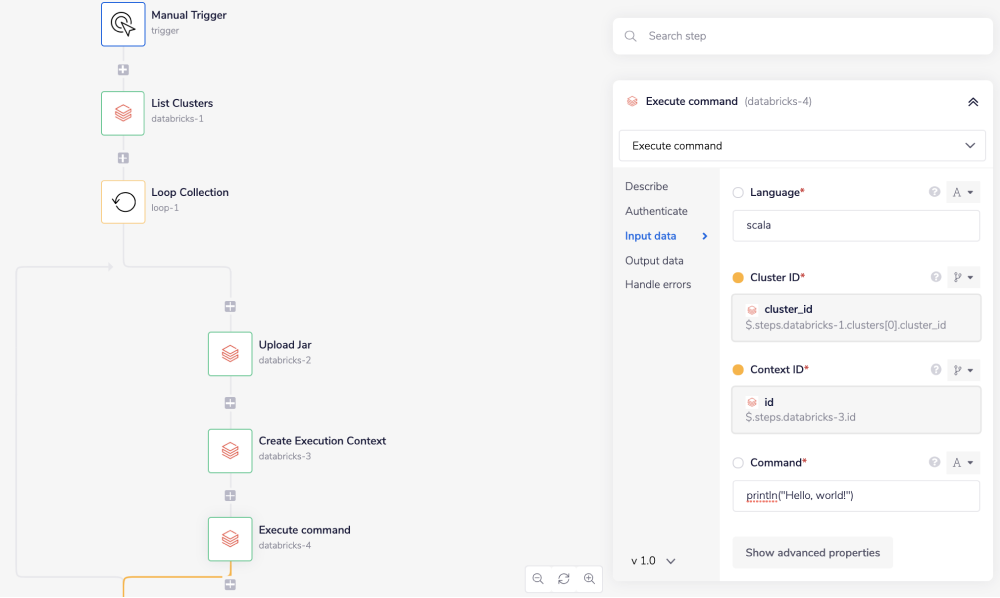
The last step is to drag another Databricks connector onto your workflow and set the operation to 'Execute command'.
You will need to provide jsonpath for the 'Language' and 'Cluster ID' fields. Provide the jsonpath in the same way as you did in the previous step.
Use the connector-snake to find the jsonpath for the 'Context ID' field from the 'Create execution context' step. It should appear similar to
This will create an execution context in each of your clusters.
The last step is to drag another Databricks connector onto your workflow and set the operation to 'Execute command'.
You will need to provide jsonpath for the 'Language' and 'Cluster ID' fields. Provide the jsonpath in the same way as you did in the previous step.
Use the connector-snake to find the jsonpath for the 'Context ID' field from the 'Create execution context' step. It should appear similar to $.steps.databricks-3.id.
Type in the command you would like to run in the 'Command' field.