Calling Other Workflows
Setting up parallel processing and modular functions in Tray
Overview
When processing data in Tray there are three primary factors to be taken into consideration:
- The complexity of the processing
- The number of processing actions to manage
- The volume of data being processed
If your data processing is both simple and low-volume, then you will likely be able to build a single workflow which will meet your needs, and it will be simple to understand and maintain.
However, if your data processing is complex (particularly if there are multiple processing actions to manage) then it is highly recommended to use a callable workflow for each processing action.
This will enable you to work with a set of simpler 'parent and child' workflows which are easier to understand and maintain than one large sprawling workflow.
Likewise, if you are processing e.g. 10s of 1000s of rows of data, the processing actions should be sent to callable workflows.
This will allow you to send data in batches which will then be processed in parallel, as opposed to each batch waiting for the previous to finish, as would be the case if the processing was down in the main parent workflow.
Example callable project
So in practice you could end up with an extremely simple main workflow which looks something like this:
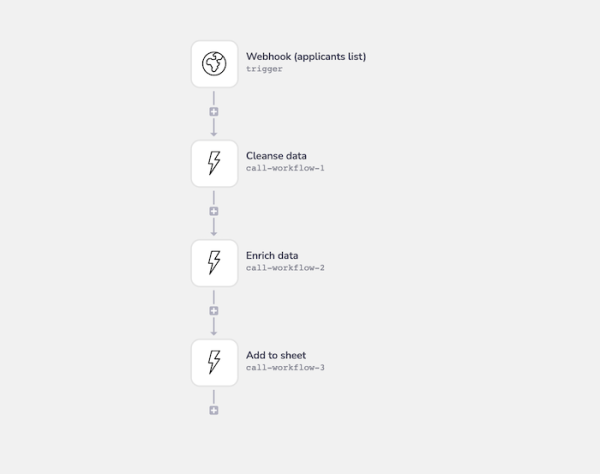
The above example begins with the following 'applicants' dataset:
It then 'cleanses' it by mapping several 'favorite_color' values ('n/a', 'none' and 'unspecified') to 'null' in order to ensure consistency.
Before enriching it with the following dataset which contains the same applicants favorite tv shows:
And then sending the final list to Google Sheets.
It takes the following steps to achieve all this:
Note on complexity
The processing carried out in all of the above callable workflows is deliberately very simple for demonstration purposes.
If the processing was that simple you would arguably do it all in the main workflow!
However, your processing may be as complex as the following example, in which case it is imperative that you use a callable workflow:
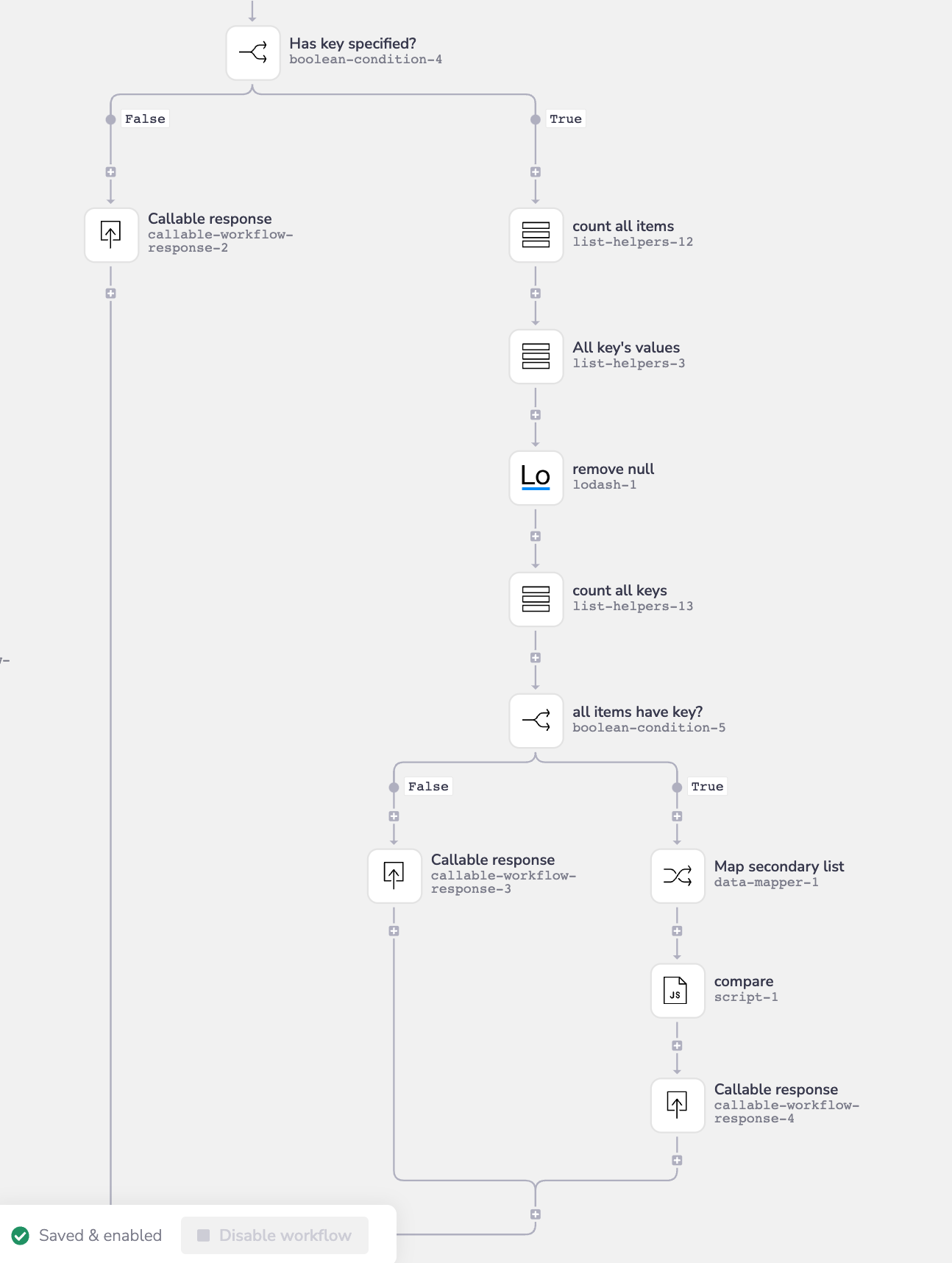
Waiting for callable workflows to respond
The above example uses callable workflow responses as it is required in order to retrieve the data from each step in order to pass it on to the next processing step.
However, this may not be necessary.
For example a callable workflow might be simply compiling and sending notification messages.
Or the callable may be processing data and sending to a destination service / database in one go.
In which case, you should use the** 'Fire and forget' operation**.
When using Fire and Forget you will need to be extra sure that the callable workflows have the correct monitoring and error handling systems built in.
Note that, if your main workflow needs a response before continuing to downstream actions, and you are processing large volumes of data, then you may need to use workflow threads as explained below.
Processing large volumes of data
If you are processing e.g. 10s of 1000s of rows of data at a time, you can send these rows in batches to callable workflows and they will be processed 'in parallel'.
This has two benefits:
- The main workflow which is responsible for creating the batches can work much faster because it is only focused on this one task.
- The secondary processing workflows can process multiple runs simultaneously. So your workflow batches do not have to wait in a queue until the previous batch is finished.
The following diagram is a good illustration of how this works:
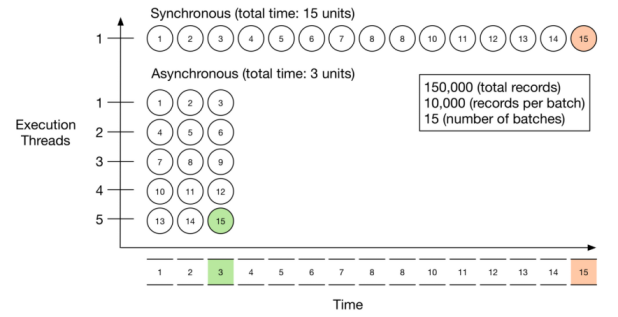
This can massively reduce the overall processing time - i.e. 10 batches of records will take a 1/10th of the time.
The following example illustrates a project which makes use of this approach:
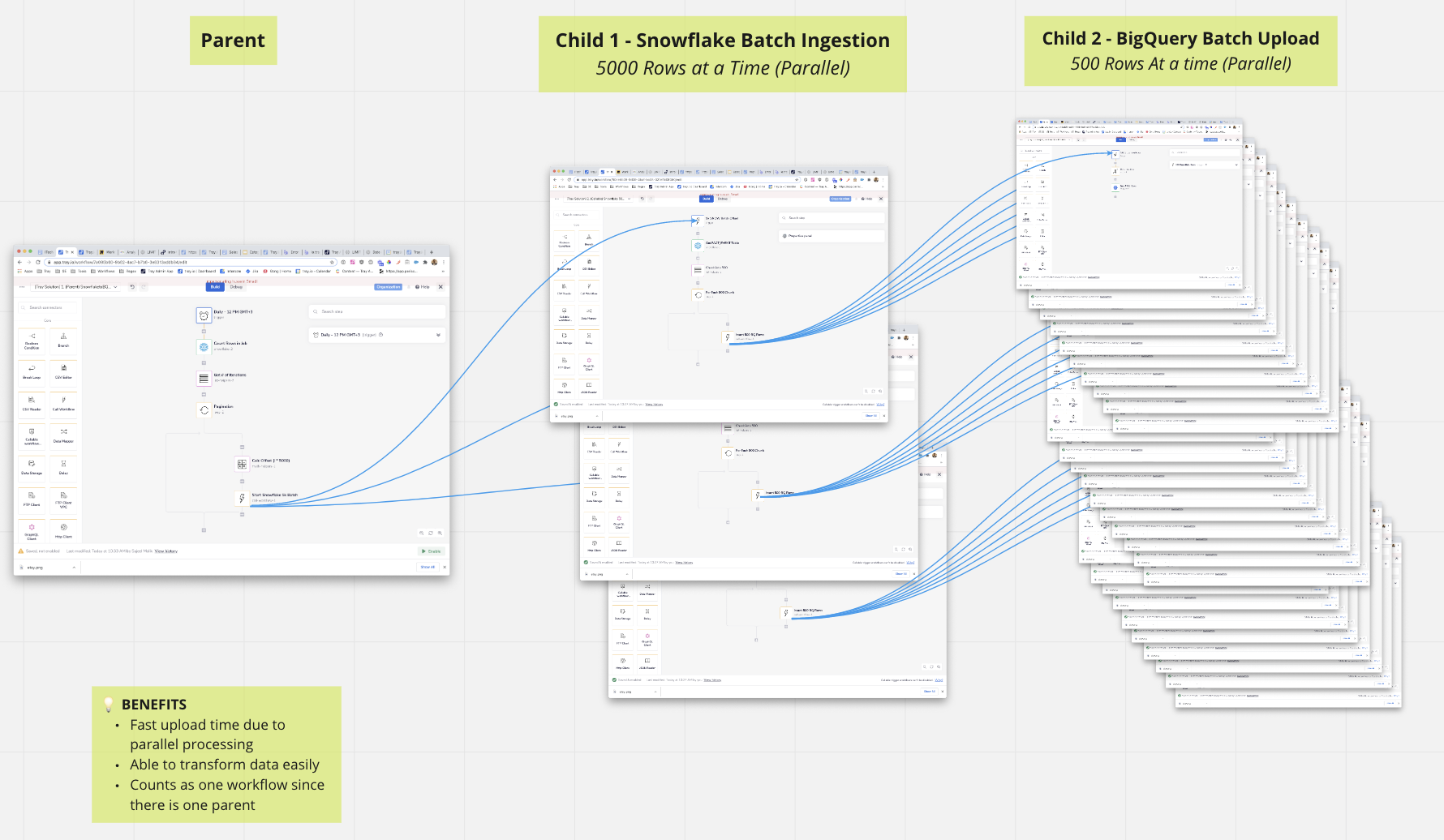
Here, the parent workflow kicks off processing workflows where:
- Child 1 ingests batches of 5000 Snowflake rows (the maximum which can be pulled from Snowflake at one time)
- Child 2 separates each batch into batches of 500 to be uploaded to BigQuery (the maximum which can be uploaded to BigQuery at one time)
A very important operation to be aware of here is the List Helpers 'Chunk' operation.
In conjunction with the Loop Connector this can be used to batch your data into the required batch sizes in order to be sent to processing workflows:

Using workflow threads
In the above Snowflake / BigQuery example, the main workflow is kept very simple as it does not require a response from the processing workflows.
However there may be times when you need to both:
-
Process large volumes of data
AND
-
Receive a response from the processing workflows before continuing with further tasks in the main workflow
In this case you should follow our guide on Workflow Threads
This will show you how to:
- Keep track of threads started and finished
- Notify the main workflow when all threads have completed
- Run a monitoring system to check if the processing has been running too long
Appendix: Import and run the test callable project
Prerequisites
You will need to create a Google Sheet and:
- Add the following headers:
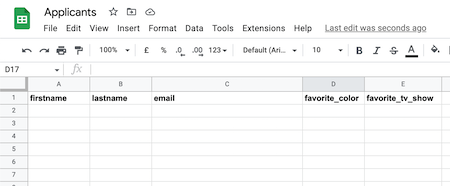
- Grab the sheet ID from the sheet url:

Import the project
Download the project by clicking on this link.
Then:
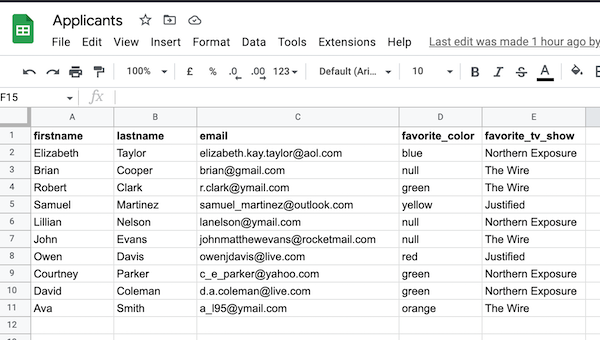
Once you have triggered a run your Google Sheet will be populated:
And you can inspect the logs in your workflows:
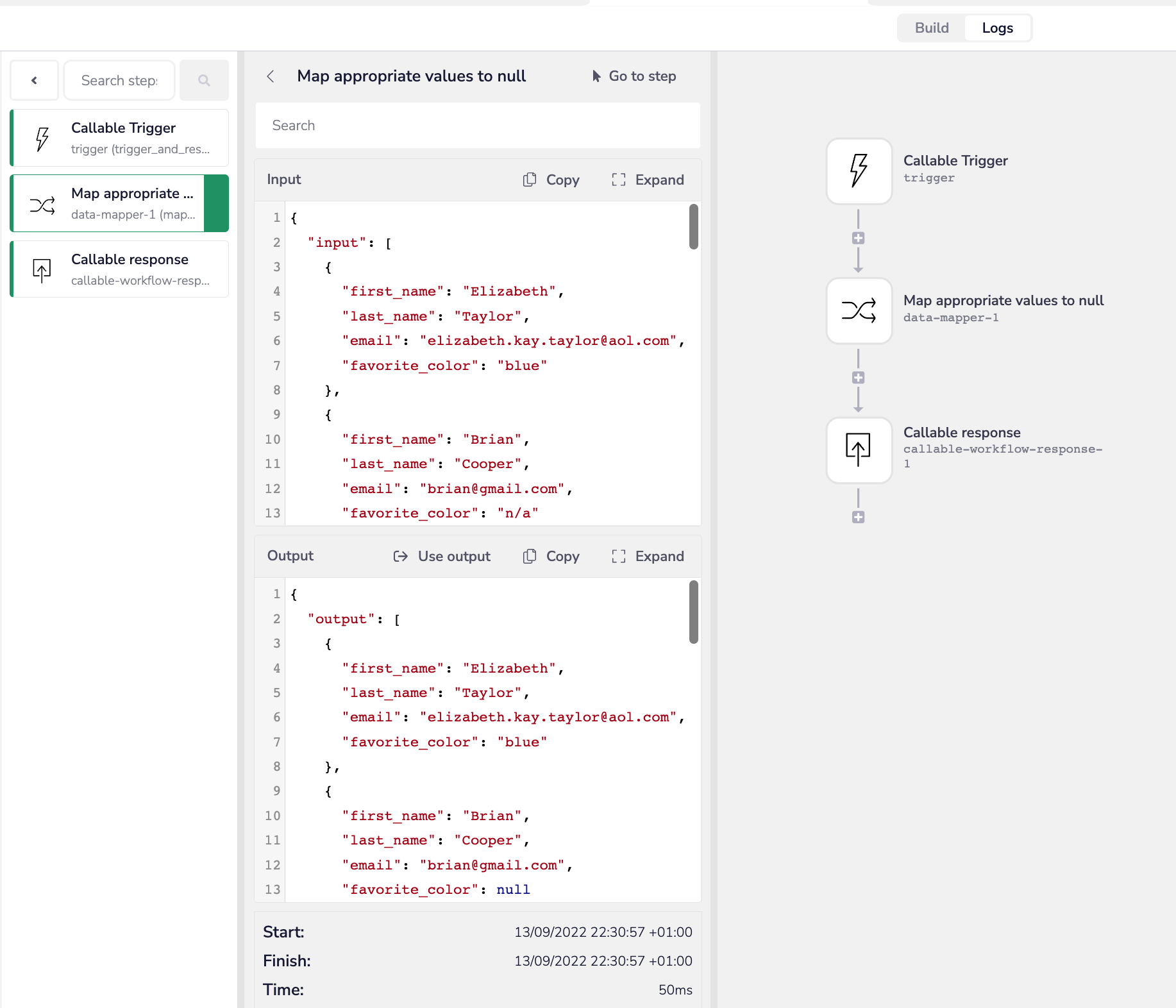
And check to see how the input schema for each callable trigger is made:
