Getting started with vector tables
Tray’s vector tables is a key feature in terms of making your organization AI-ready. Post-ingestion, it allows you to store your data in ‘vector embedding’ format, which means it is primed to work with AI systems.
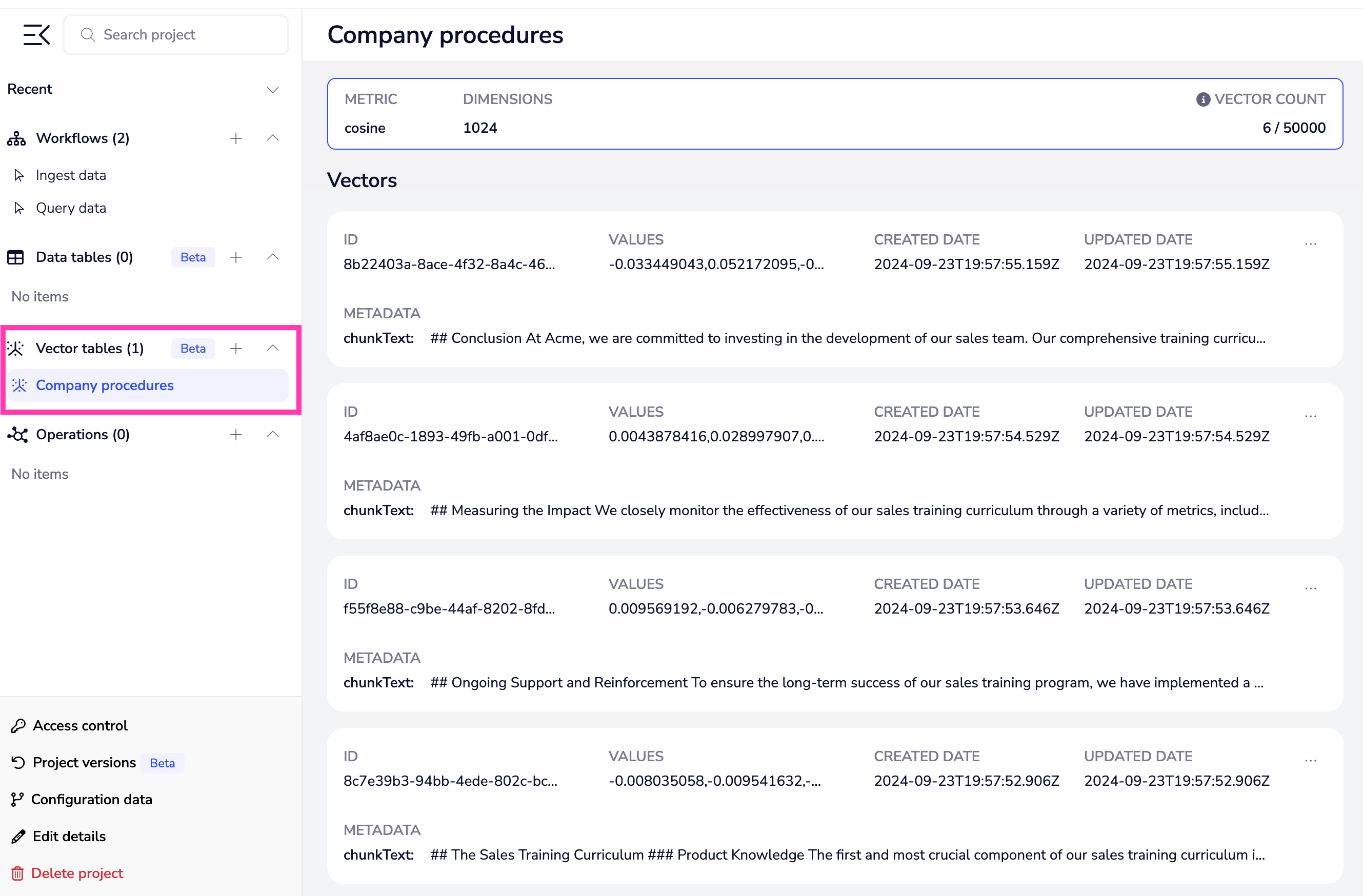 Tray’s vector tables is a key feature in terms of making your organization AI-ready. Post-ingestion, it allows you to store your data in ‘vector embedding’ format, which means it is primed to work with AI systems.
The fact that you can store your vector embeddings directly in Tray, without relying on an external database service, means you can get to POC and from POC to production in a fraction of the time.
Tray’s vector tables is a key feature in terms of making your organization AI-ready. Post-ingestion, it allows you to store your data in ‘vector embedding’ format, which means it is primed to work with AI systems.
The fact that you can store your vector embeddings directly in Tray, without relying on an external database service, means you can get to POC and from POC to production in a fraction of the time.
What are vectors?
Vectors, or vector 'embeddings', are a way to represent words or phrases as numbers in a high-dimensional space, allowing computers to understand their meaning. Imagine a map where similar words are placed close together, and dissimilar words are far apart. Each word is assigned a unique set of coordinates (the vector) that captures its meaning, so words with similar meanings have similar coordinates. This way, we can calculate the distance between words and understand their relationships. This is what enables powerful retrieval systems based on finding closest matching vectors. Retrieved matches can then be passed on to LLMs such as ChatGPT and Claude to enable tools like chat interfaces and simple Q&A knowledge agents.
How do I use vector tables?
Adding data to vector tables
After creating a new vector table, you will need to manage a content ingestion pipeline.
This is generally done with the following basic steps:
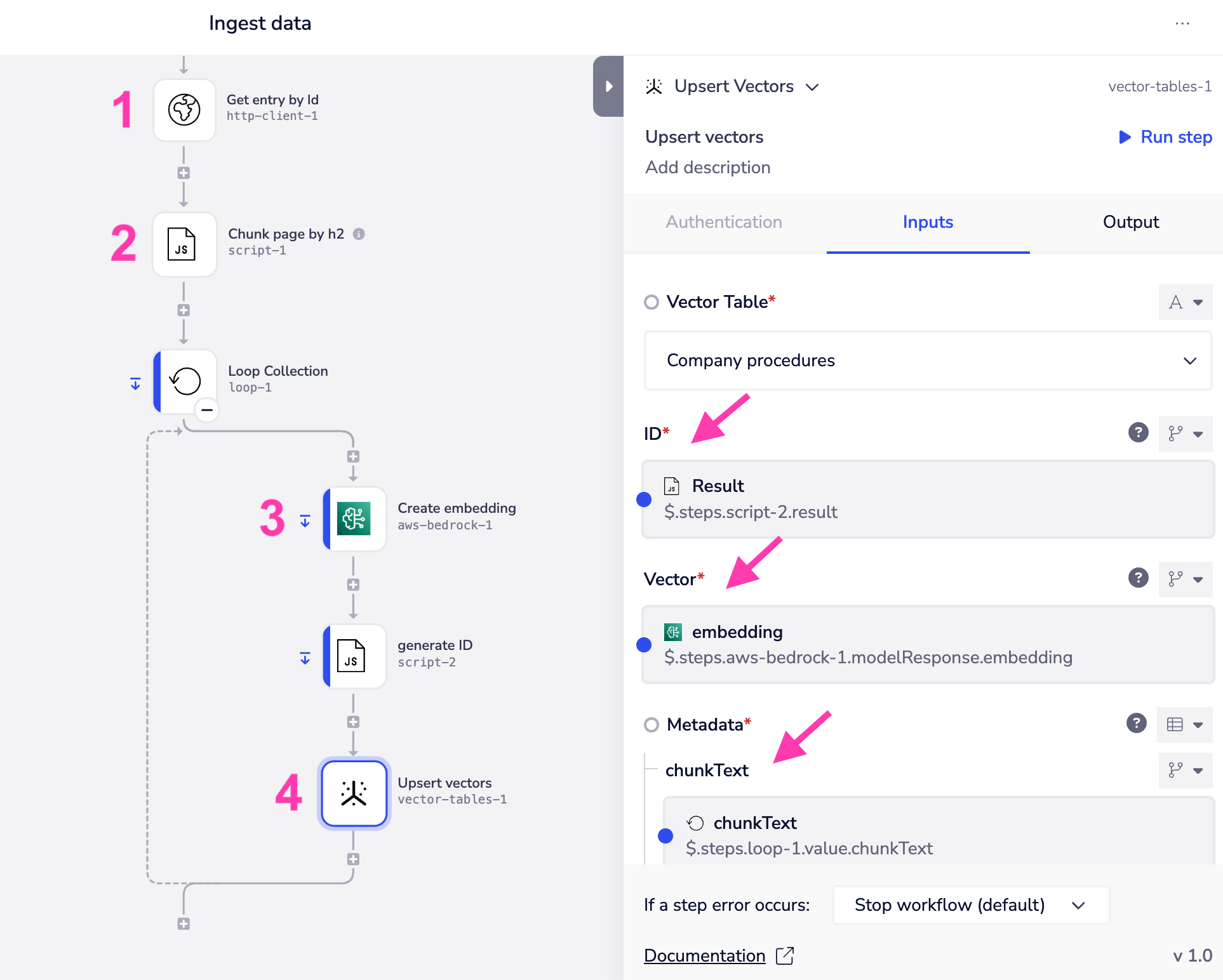
- **Ingest the data **you want to store for use by AI systems. In the above screenshot this is represented by an http client step which retrieves some content from source
- Use an appropriate script step to **break your data down into optimally-sized ‘chunks’ **(check out our templates)
- Create a **vector embedding for each 'chunk’ **of data (using e.g. the Amazon titan embed text v2.0 model)
- Assign a unique id and add each chunk of data to the vector table (using the Vector tables
upsert_vectoroperation). From the above screenshot you will see that each entry must have values for the following:
- A unique ID
- A Vector (the result from the ‘create embeddings’ step)
- **Metadata **which includes, at a minimum, the original text that is represented by the vector embeddings
Retrieving data from vector tables
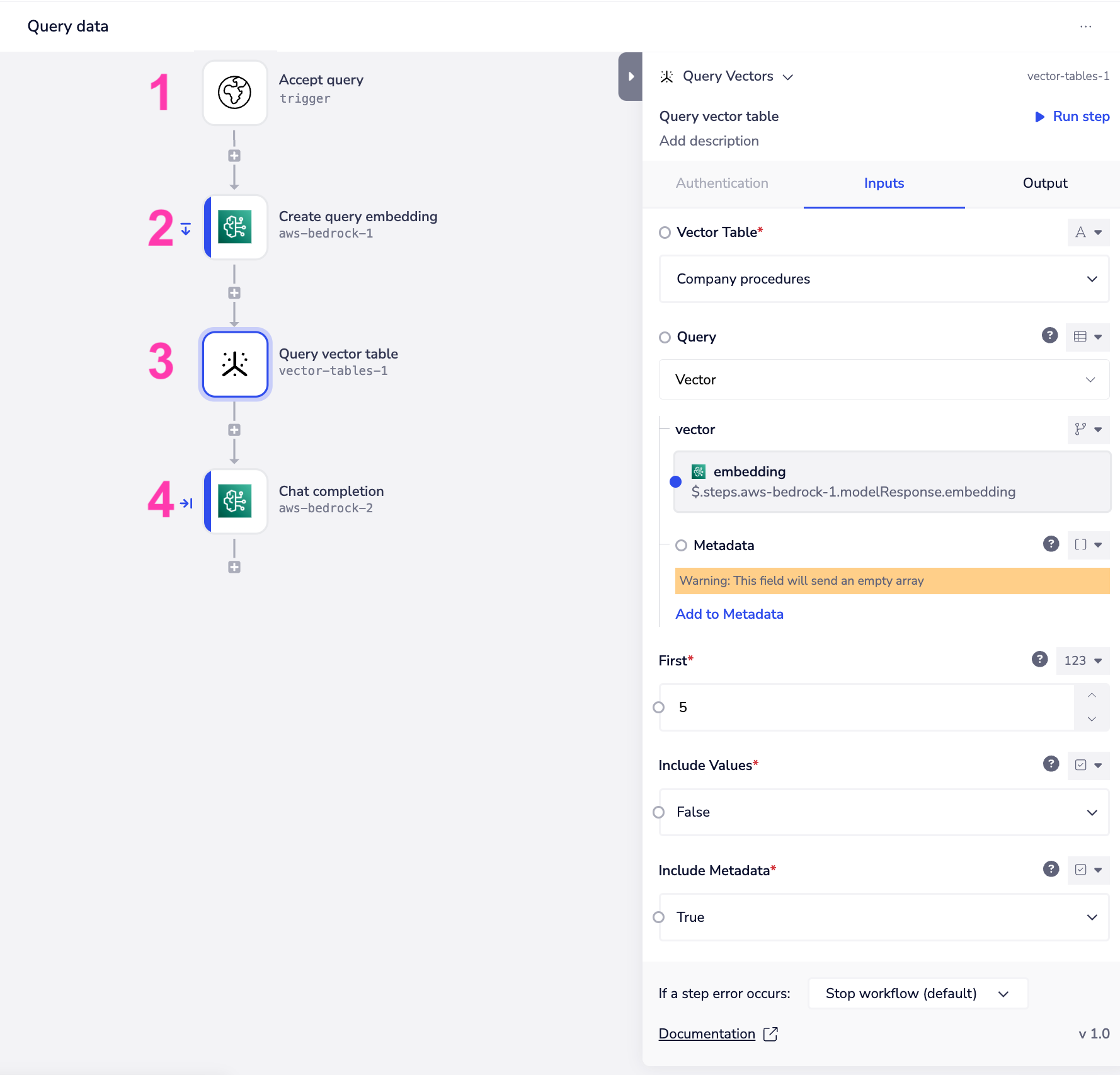
The following screenshot illustrates a typical process when retrieving vectors from a vector table:
 These steps are:
These steps are:
- **Accept a query **(e.g. a webhook picks up incoming questions from staff / users such as 'In the onboarding process what sales techniques are we trained on?')
- **Create a vector embedding of that query **(using the same model that was used to create the vector embeddings of the content stored in your vector table)
- Use the Vector tables
query vectoroperation to retrieve the closest matches from the vector table:
- The vector (the result of the ‘create query embedding’ step)
- First to specify the number of closest matches to return
- Include Values can be used to return the actual vector embeddings (not generally required)
- Include Metadata is generally required as this will include, at a minimum, the original chunked content associated with the vector embeddings
- Make use of the query vector results by e.g. passing to an LLM for a chat completion. A chat completion will generally include:
- The chunked text from the top x results from the vector table query
- The original natural language query asked by the user
- A system prompt to give the LLM context around what its role is and how it should answer the user’s query
Deleting data from vector tables
You have two options for deleting vectors from a vector table:
- Use the connectors within a workflow to delete vectors
- Use the delete all vectors button in the vectors list view