Optimizing vector tables
Making optimal use of Tray's built-in vector tables
Managing your vector ingestion pipeline
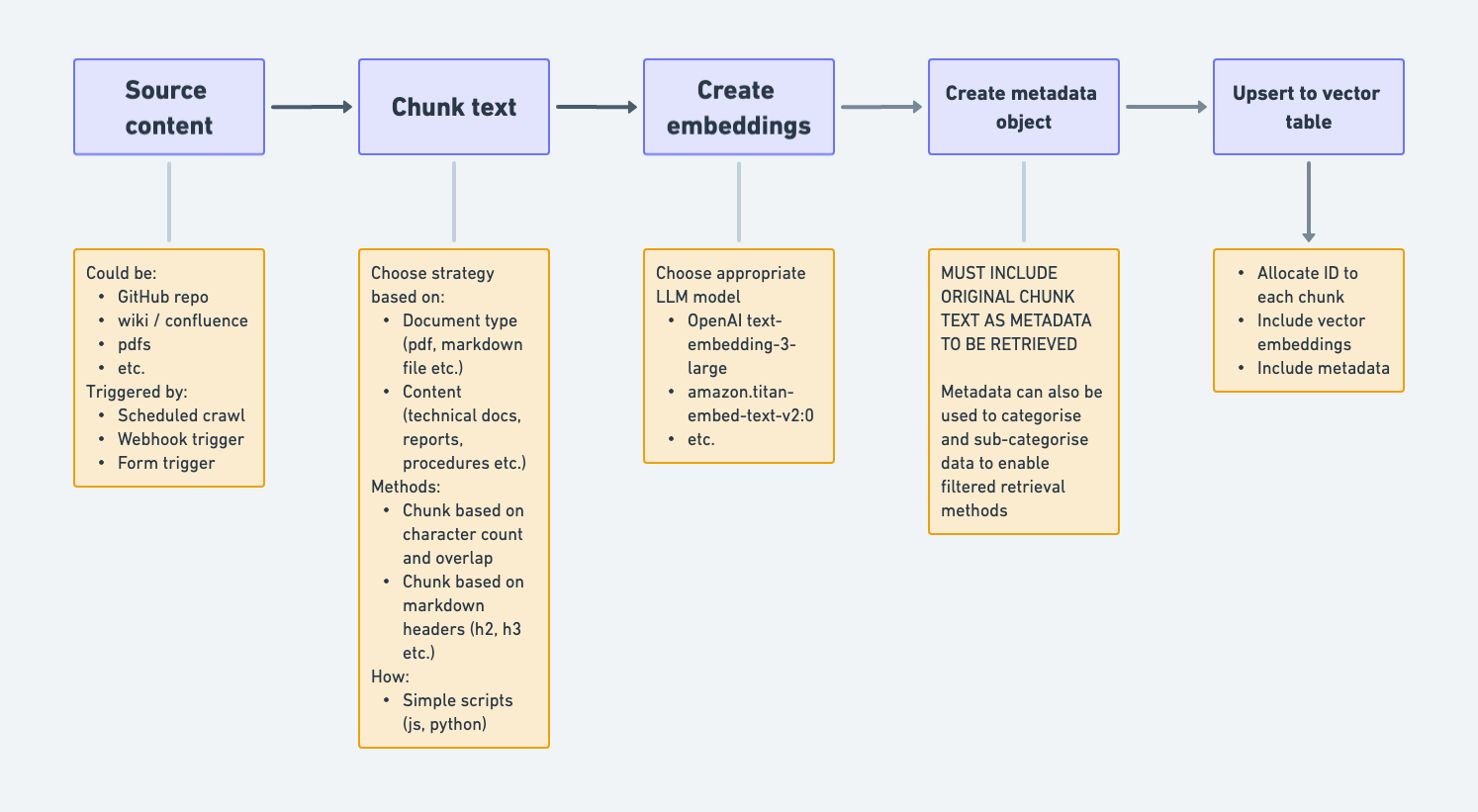
The following diagram gives an overview of the process involved in building a 'vector ingestion pipeline':
Sourcing content
The first stage in indexing content to a vector table is to retrieve it from source - e.g. internal wiki / Confluence, external documentation site, internal databases. Exactly how you do this will depend on the source and the storage system - you could be crawling a GitHub repository, or you might be using a custom-built crawler via the HTTP client. Depending on the system you are building it is important to remember that you will likely need to manage two processes when it comes to sourcing and chunking your content:
- The initial chunking and loading of content to build your vector table-based system from scratch
- The maintenance of your vector tables - chunking of new and updated content This may not be the case however - you could be simply indexing a 'live feed' of data. For example you could be monitoring Slack channels or community discussion groups for content. In this case your ingestion pipeline might be triggered by a custom webhook trigger, or you could be running a scheduled trigger to check for new content.
Chunking content
Before creating embeddings and uploading to a vector table you will need to decide on a chunking strategy.
For example you may wish to chunk by header (markdown or html) - getting all text between headers (this assumes well-structured content where the character count between headers is consistent and not excessively large)
Another strategy is by character count - including defining an 'overlap' between chunks to maintain context (this is more appropriate for unstructured content or content that is not uniformly structured.
It may be that you wish all content to be chunked in the same manner, or there may be certain types of content that will be suited to one method and other types to the other.
In this case you can use conditional logic to dynamically decide your chunking strategy.
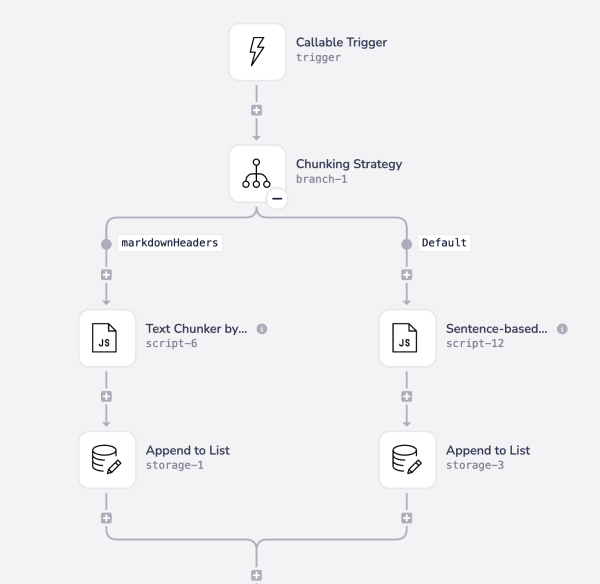 It may also be that you do not require chunking at all - e.g. there might be certain document types that have minimal content and so do not require chunking:
It may also be that you do not require chunking at all - e.g. there might be certain document types that have minimal content and so do not require chunking:
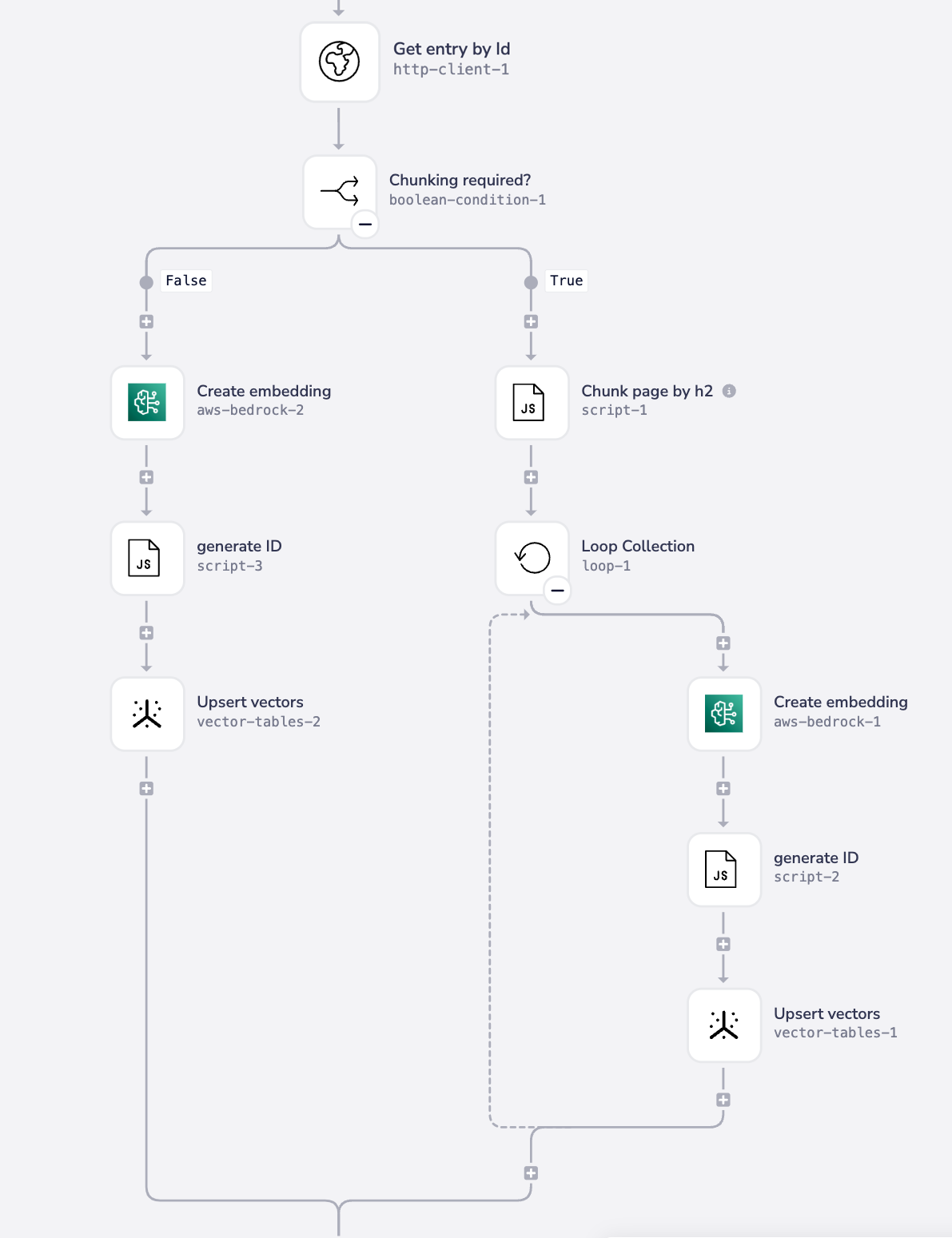
Creating embeddings
To create the vector embeddings which represent your chunks of content, you can make use of whichever Embeddings model you wish (using OpenAI, AWS Bedrock, Cohere or the HTTP client for any other models available via API)
The key point here is that you must pass the chunked text as the input:
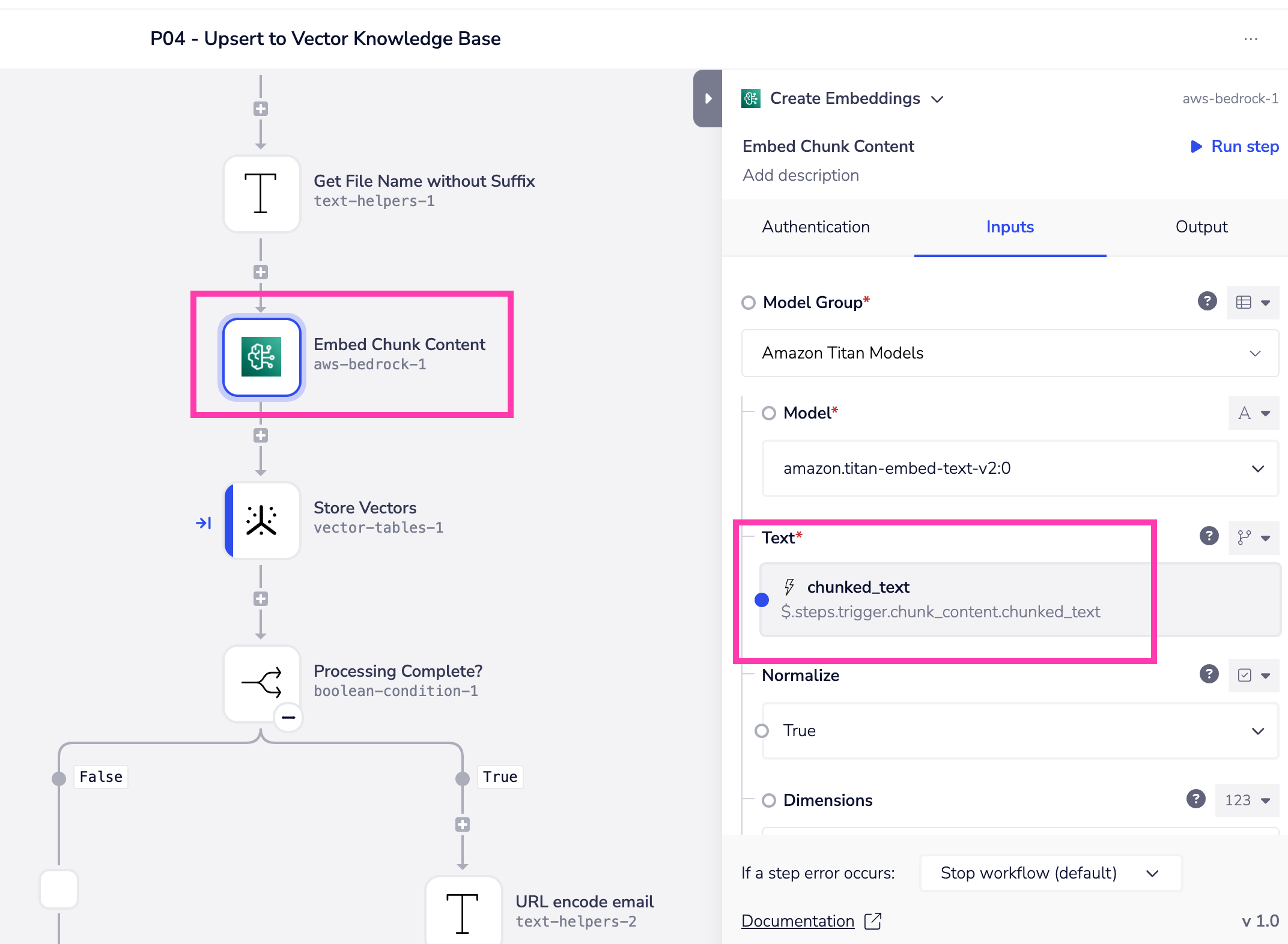 This will then return the vector representation of the chunked text in the form of an array of e.g. 1024 numbers (depending on the model you have chosen).
This array must then be passed on as part of the upsert to the vector table, alongside the metadata and original chunked text for that particular chunk.
This will then return the vector representation of the chunked text in the form of an array of e.g. 1024 numbers (depending on the model you have chosen).
This array must then be passed on as part of the upsert to the vector table, alongside the metadata and original chunked text for that particular chunk.
Creating metadata and upserting vectors
Note the following points when upserting vectors:
- Each vector entry must have a unique id. One strategy you could adopt is to use the source id from your content storage system, and append the chunk number
- Be sure to include your original source text / content in the metadata that is part of your embeddings object so that it can be retrieved for subsequent chat completion operations
- Metadata can be constructed dynamically - e.g. you could deconstruct urls to extract categories and subcategories for your content and chunks
Looking in more detail we can see an example metadata object for the upsert vector operation:
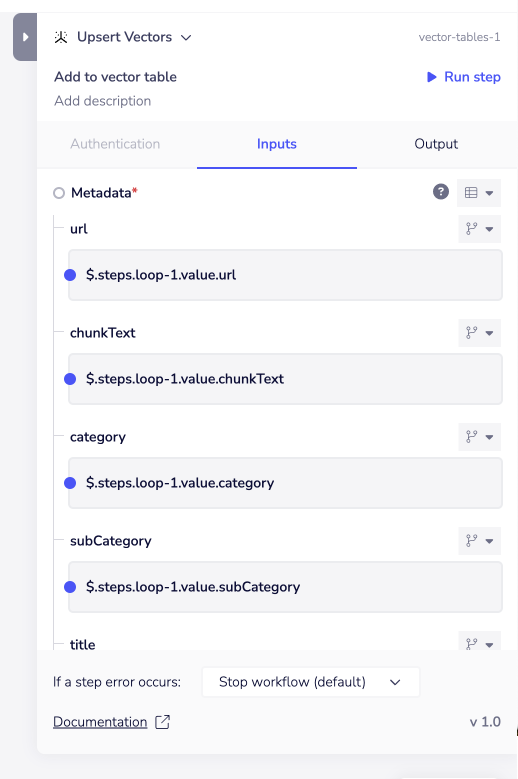 The following are some metadata examples which might give some ideas for how you want to structure your metadata:
The following are some metadata examples which might give some ideas for how you want to structure your metadata:
\{
"chunk_id": "3f7351cd-4d4d-4b37-b56d-309894d2f37d",
"source_page_id": "17eaf74c",
"title": "Sales Onboarding Process",
"content": "Welcome to the Sales Team! This document serves as a comprehensive guide to our Sales Onboarding Process, designed to equip new team members with the knowledge, skills, and resources necessary to succeed in their roles.",
"type": "procedure",
"authors": [
"Sales Team"
],
"publication_year": "2022",
"source": "Company Wiki"
\}
\{
"source_page_id": "f5a3d18f",
"chunk_id": "f5a3d18f-0",
"chunk_count": 6,
"chunk_title": "Configuring Single Sign-On (SSO) with SAML",
"chunk_content": "Text content of the chunk",
"chunk_summary": "Brief summary of the chunk",
"category": "security",
"sub_category": "sso",
"source_url": "https://acme.com/docs/administration/security/authentication/single-sign-on/saml-configuration",
"source_document_title": "Security and Authentication Guide"
\}
Constructing metadata in this way can enable you to build a 'hybrid' retrieval system whereby you can use metadata filters to narrow the focus of your vector retrieval. For example, you may have a system of classifying the queries that come into your chat completion workflow so if a query has been identified as a 'security' question then you could use a metadata filter to say "give me the top 10 vector matches for this query that are in the category of 'security'"
Managing source content updates
As implied by the name the 'upsert vector' operation will either:
- create a new entry in the table if the specified vector id does not exist
- update the entry if it does exist. When it comes to updates to your source content, this may be useful if your content has not actually been chunked, or you have stored the id of individual chunks in a way that you can identify what needs upserted. A likely more practical approach, however, is to delete all chunks with the same source id and re-chunk the edited source page and add to the vector table as per the following workflow. In order to do this a recommended approach is to adopt the following convention for setting your vector IDs:
- Use the pattern
source_id-chunk_numberwhere source_id is the ID of the source page andchunk_numberis a zero-indexed integer which is incremented with each chunk - While creating embeddings and preparing metadata, capture the total number of chunks for each
source_id - Add the
chunk_countto the metadata field of thesource_id-0vector (or to all chunks) - Upsert the vectors with the
source_id-chunk_numberas the ID This will then enable you to build a content update workflow such as the following: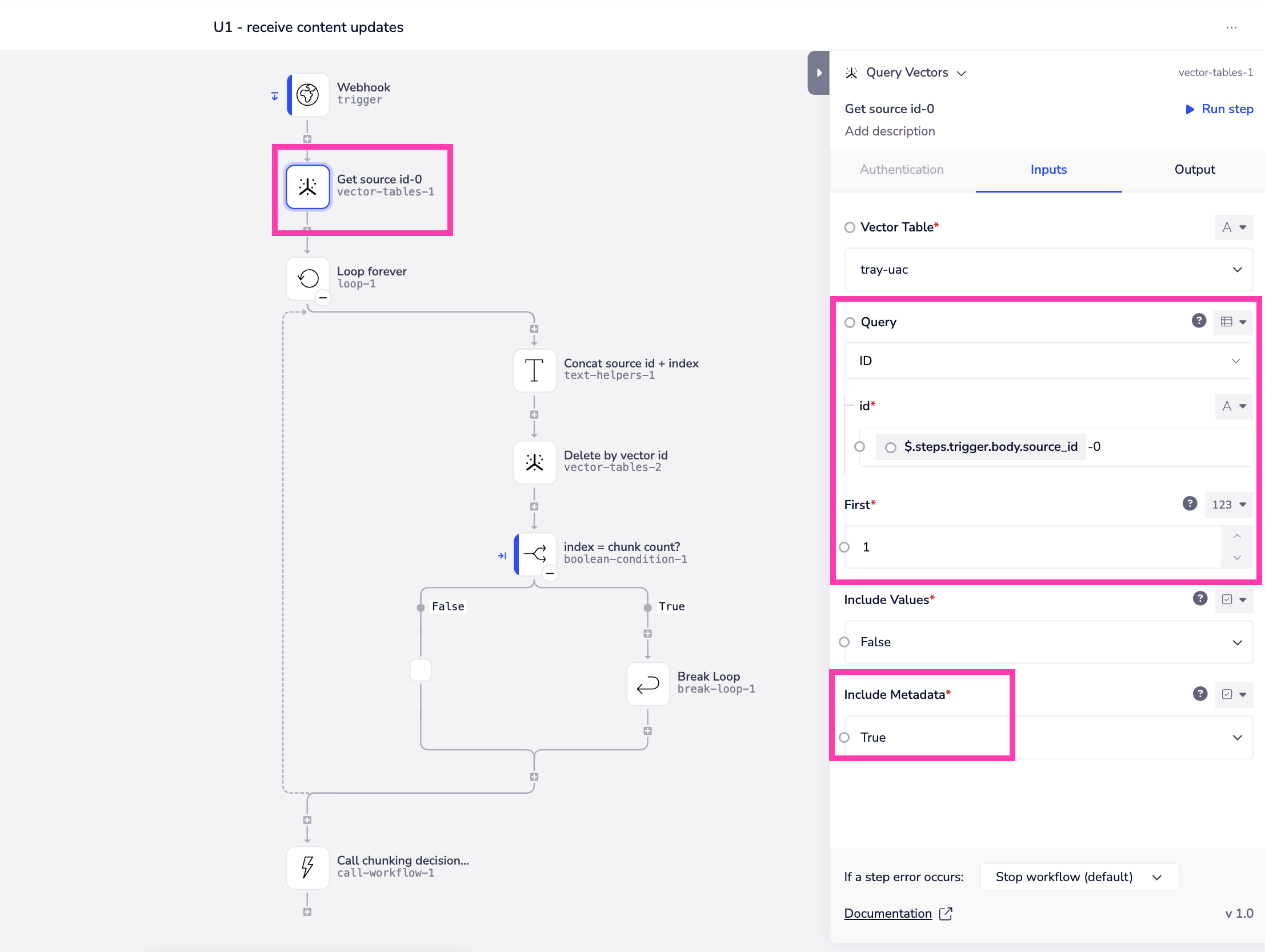 This workflow:
This workflow:
- Receives a webhook update containing updated content and the source page id
- Uses 'query vectors' to retrieve the vector of the first chunk i.e.
source_id-0 - Starts a loop forever and uses the index of each run of the loop to retrieve the chunks matching the
source_idi.e.:
source_id-0source_id-1source_id-2- Once the index of the loop matches the
chunk_countreturned by the query vector step, the loop is broken
- Sends the updated content to the chunking stage of your ingestion pipeline
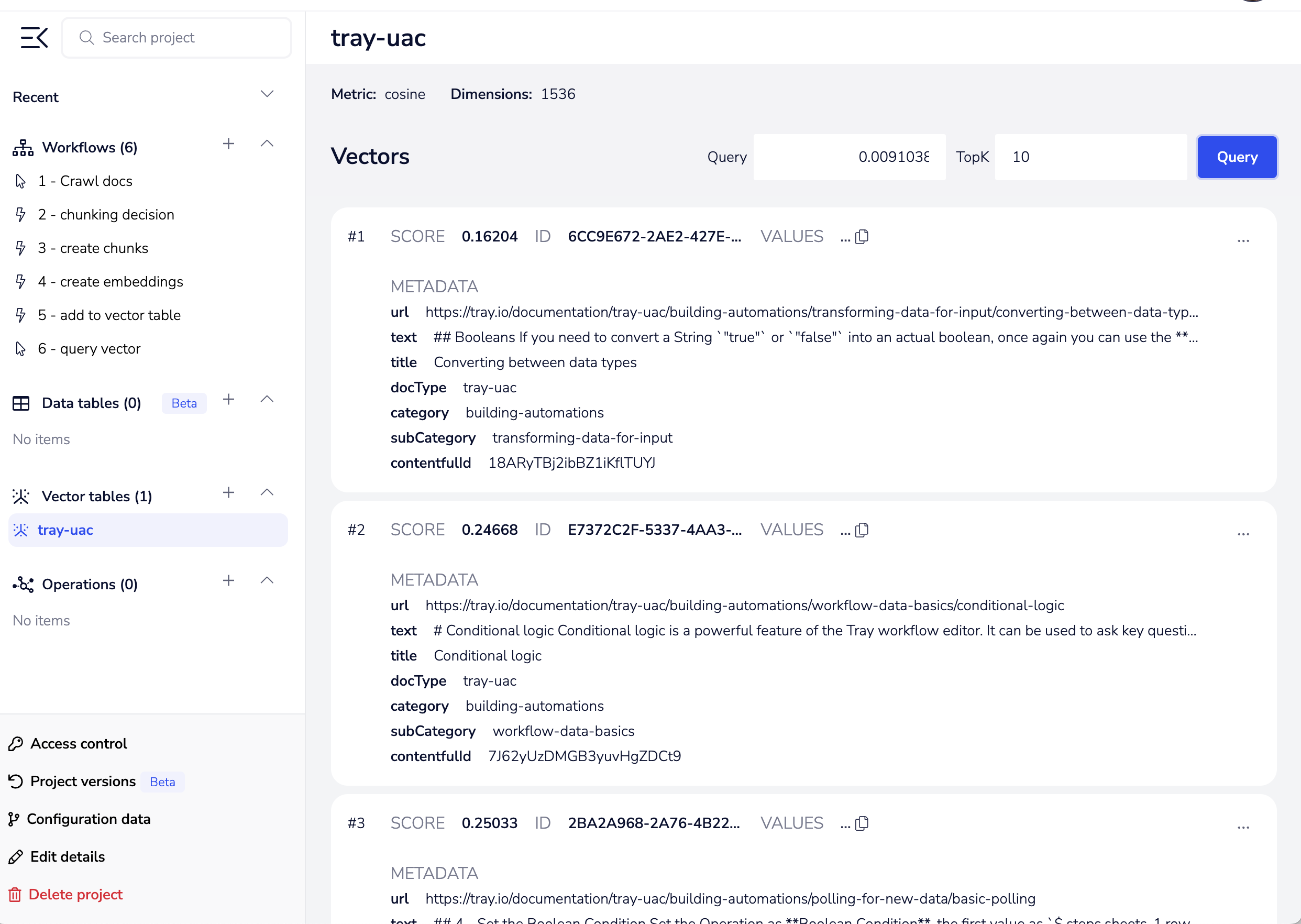
Retrieving vectors
Relevance scoring
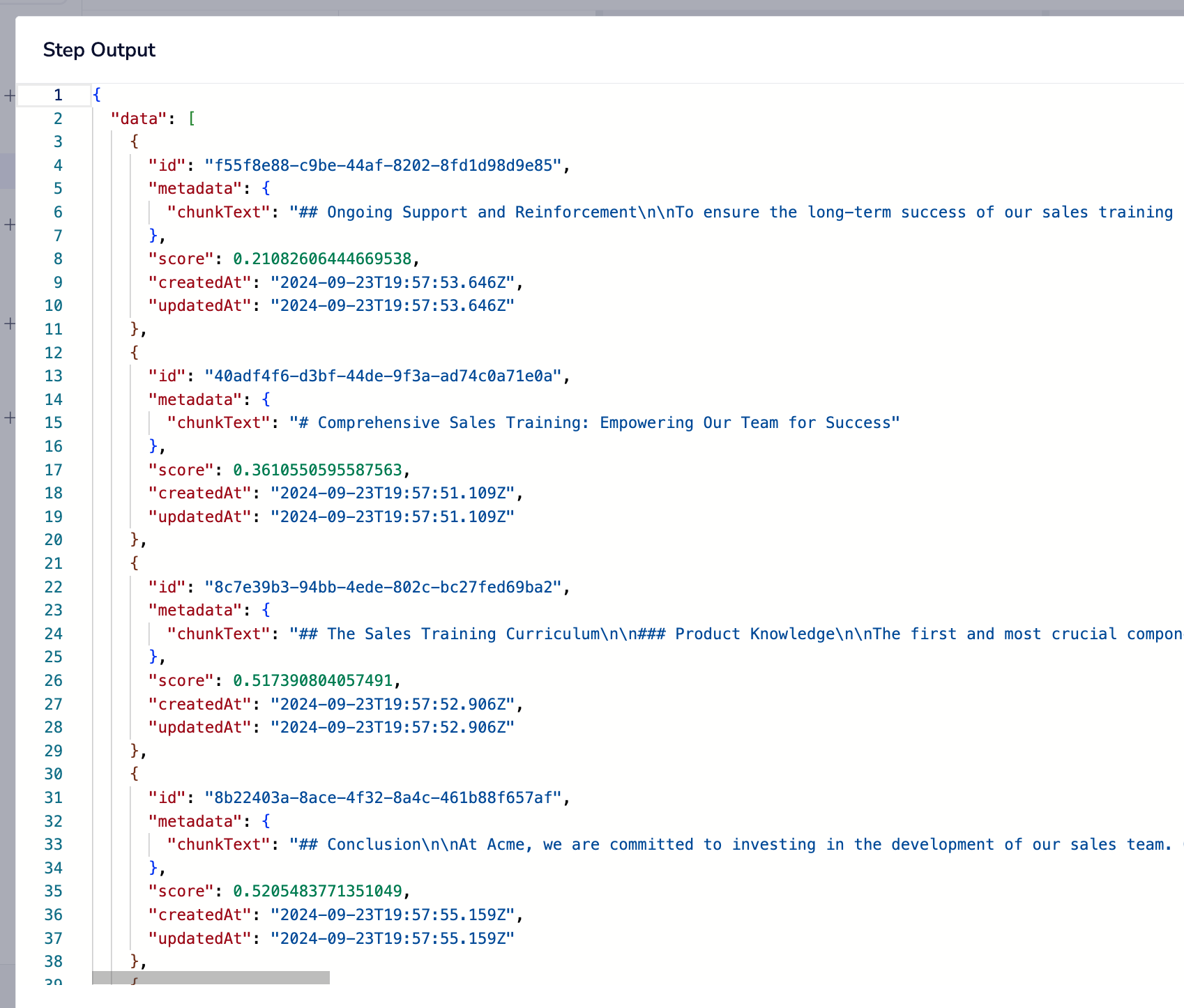 When using the 'query vectors' operation each returned result will have a 'score' which indicates how close a match that embedding is to the query vector.
The closer the score is to 0, the closer the match. Thus you could then use a boolean connector to e.g. remove all results where the 'score' is greater than 0.2
When using the 'query vectors' operation each returned result will have a 'score' which indicates how close a match that embedding is to the query vector.
The closer the score is to 0, the closer the match. Thus you could then use a boolean connector to e.g. remove all results where the 'score' is greater than 0.2
Including chunked content
When using the 'query vectors' operation you will invariably want to make sure 'include metadata' remains set as true (as per default) as this will enable returning the original text / content associated with the embedding for use downstream in your workflow.
Filtering by metadata
When using the 'query vectors' operation It is possible to filter using metadata (please see guidance on metadata above).
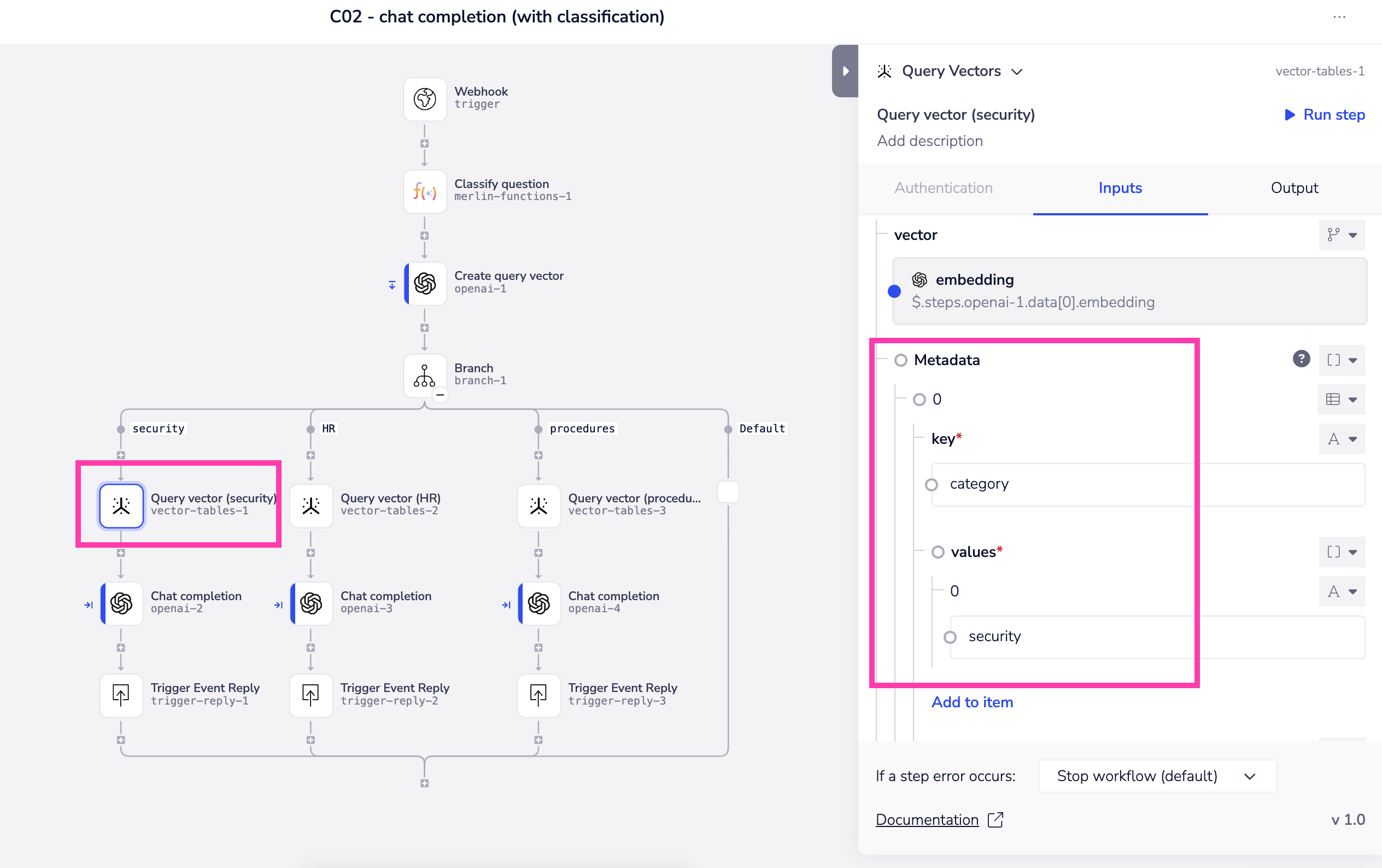
An example of when this might be useful is if you have used e.g. Merlin functions to classify the question coming in and have identified that it is on the subject of security.
Therefore you use the metadata filter to only return vectors in the category of security:
Important notes on using vector tables
Error handling
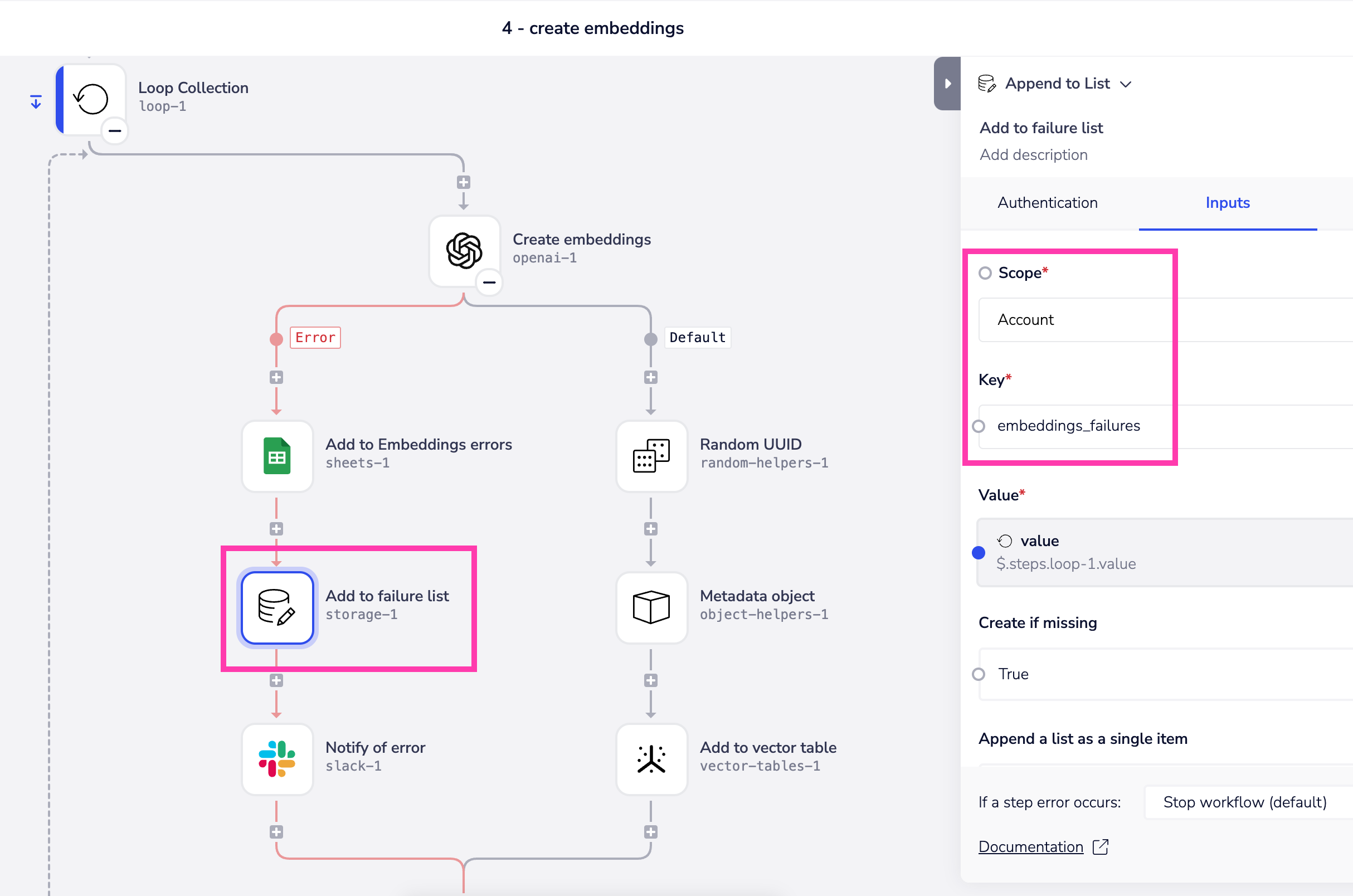
It is important to identify any potential points of failure in your vector table pipeline. One potential point of failure is the point at which you create the embeddings using an embeddings model. Here the service may return the occasional 500 error, which will result in content failing to reach the vector table. One solution for this is to use manual error handling to:
- Add to an Embeddings errors sheet
- Use account-level data storage to add to e.g an 'embeddings_failures' list
- Notify of the error
- Build a retry workflow which retrieves the errors list and attempts to create the embeddings and process to the vector table (this could be a manual- or schedule-triggered workflow)