Workflow threads
When dealing with large amounts of data, workflow threading is a technique which can greatly help manage the efficiency and reliability of your workflows.
When dealing with large amounts of data, workflow threading is a technique which can greatly help manage the efficiency and reliability of your workflows. Threading basically involves dividing your data into batches to send them to a callable workflow for processing, and setting up a system to wait until the number of threads finished is equal to the number of threads started, before continuing to the next stage in your workflow. This massively increases the efficiency of your data processing, as each batch will be processed in a parallel 'thread', rather than waiting for each one to finish.
The threads method makes use of callable workflows and it is essentially a combination of 'Fire and forget' and 'Fire and wait for response'. The use case here is that you have a large amount of data to process which requires parallelization, but your main workflow still needs to gather the results of each thread in order to do some final processing and send to a particular destination. So before setting up a threaded implementation, be sure that this is what you require - i.e. it may be that each batch you send for processing can be truly 'fire and forget' in that the sub-processing callable workflow just needs to carry out the processing and send to the destination service. In which case you do not need to set up any of the threading mechanisms explained here.
This page will take you through how to set up workflow threads, including:
- Using account-level data storage and the 'atomic increment' operation to set up a system which counts the number of threads running and identifies when they are all complete
- Using 'environment variables' to pull the main workflow url as an identifier for the account-level data
- Monitoring and taking action if any threads are taking too long to complete
Threads example (6MB limit)
To demonstrate this we can look at a workflow which is pulling batches of records to be processed and sending them to a second workflow. Note that this workflow could be manually triggered as and when you need to use it, or it could use a scheduled trigger. The overall processing limit for this example is 6MB of data (each thread has a limit of 400KB)
- The start threads workflow
- The process batches workflow
The start threads workflow
The first three sections of the main workflow look like this:
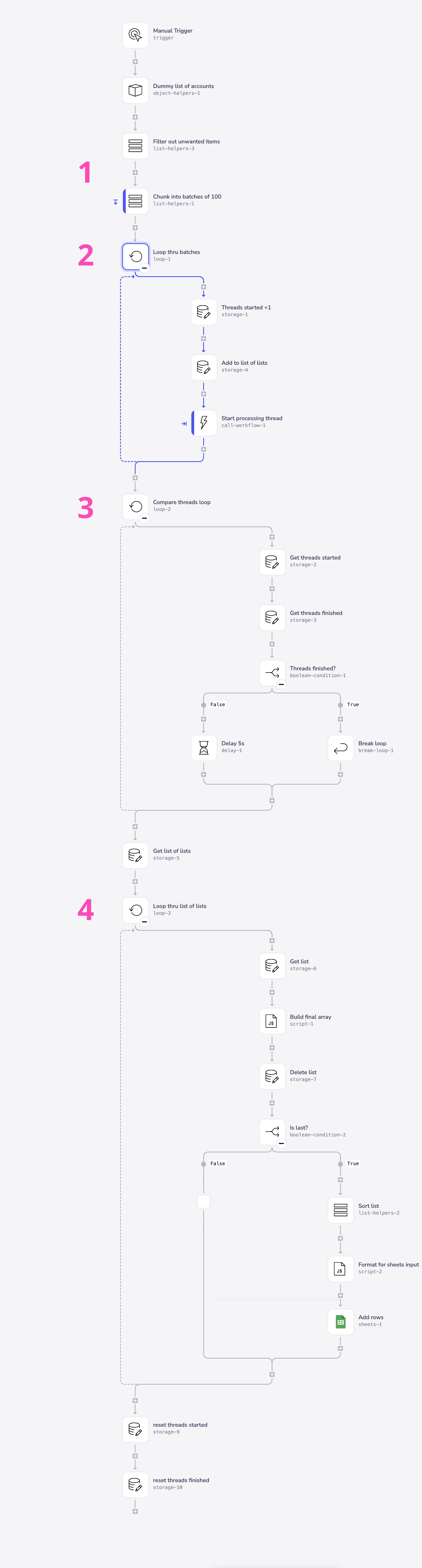 The numbered sections are explained as follows:
The numbered sections are explained as follows:
Section 1 - pre-processing and batching
Your data should be 'pre-processed' and separated into batches:
- Pre-processing may involve steps such as:
- Setting a scheduled trigger such that each run of the workflow only processes e.g 3000 records every 3 days instead of 10,000 records every week / 10 days
- Filtering out items from the list which are unwanted (e.g. all objects where status = unsubscribed)
- Some testing may be required to determine the batch size that will not overload the 400KB limit in each of the sub-processing workflows
- This example shows a dummy list of data being separated into batches using the List Helpers 'chunk' operation. A realistic scenario might involve using a third-party service 'get records' operation which has built-in filtering and pagination options that allow you to set batch size
Section 2 - send each batch for processing
For each batch we then:
- Increase the number of threads started by 1 using the Data storage 'atomic increment' operation and appending the
workflow_uuidto thethreads_startedkey stored at Account / workspace level: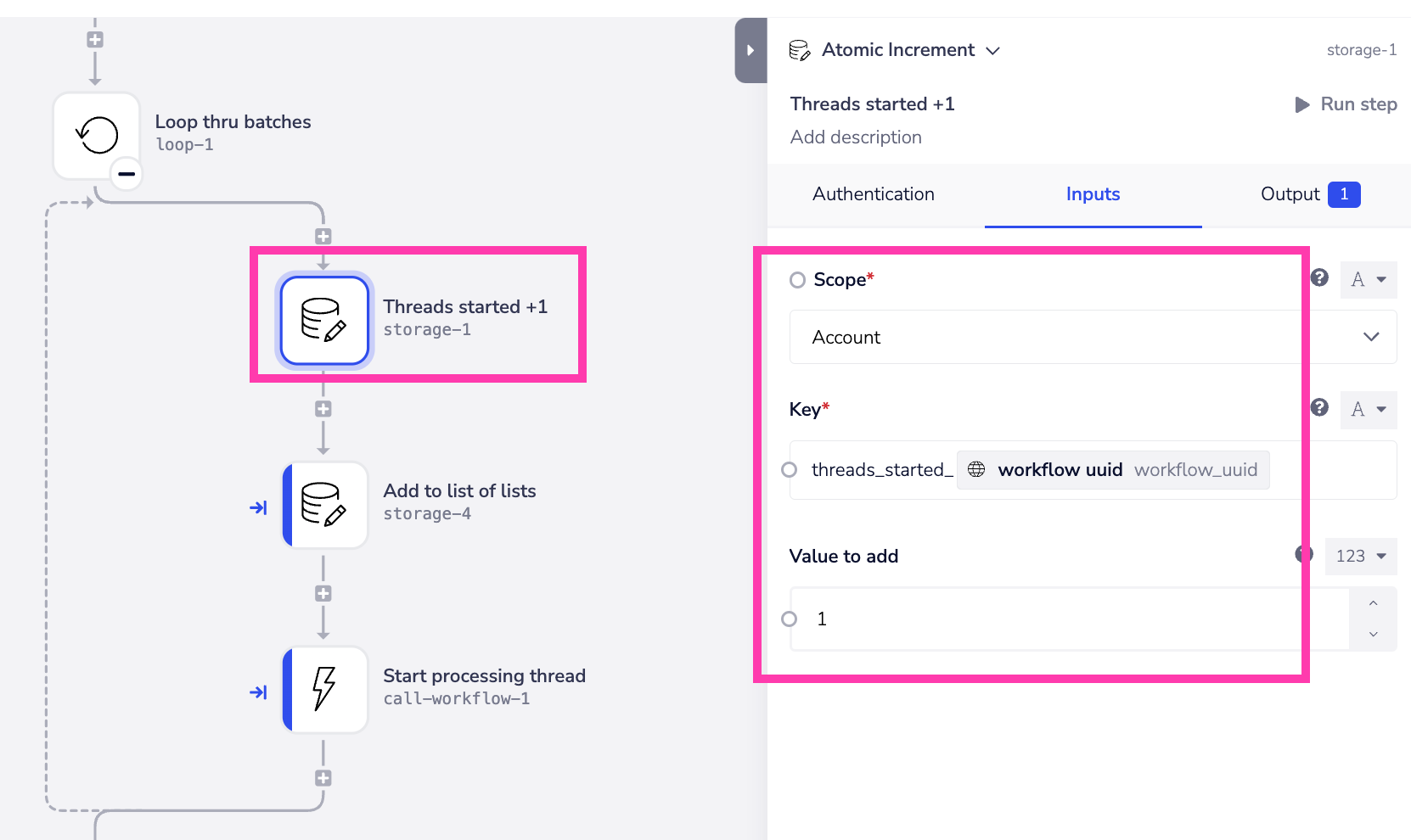
- Auto-create an incremented list with the
execution_uuidand the thread number appended to theaccounts_list_value (this can be stored at workflow level as it is just keeping a record of the lists created for retrieval at the end of this workflow):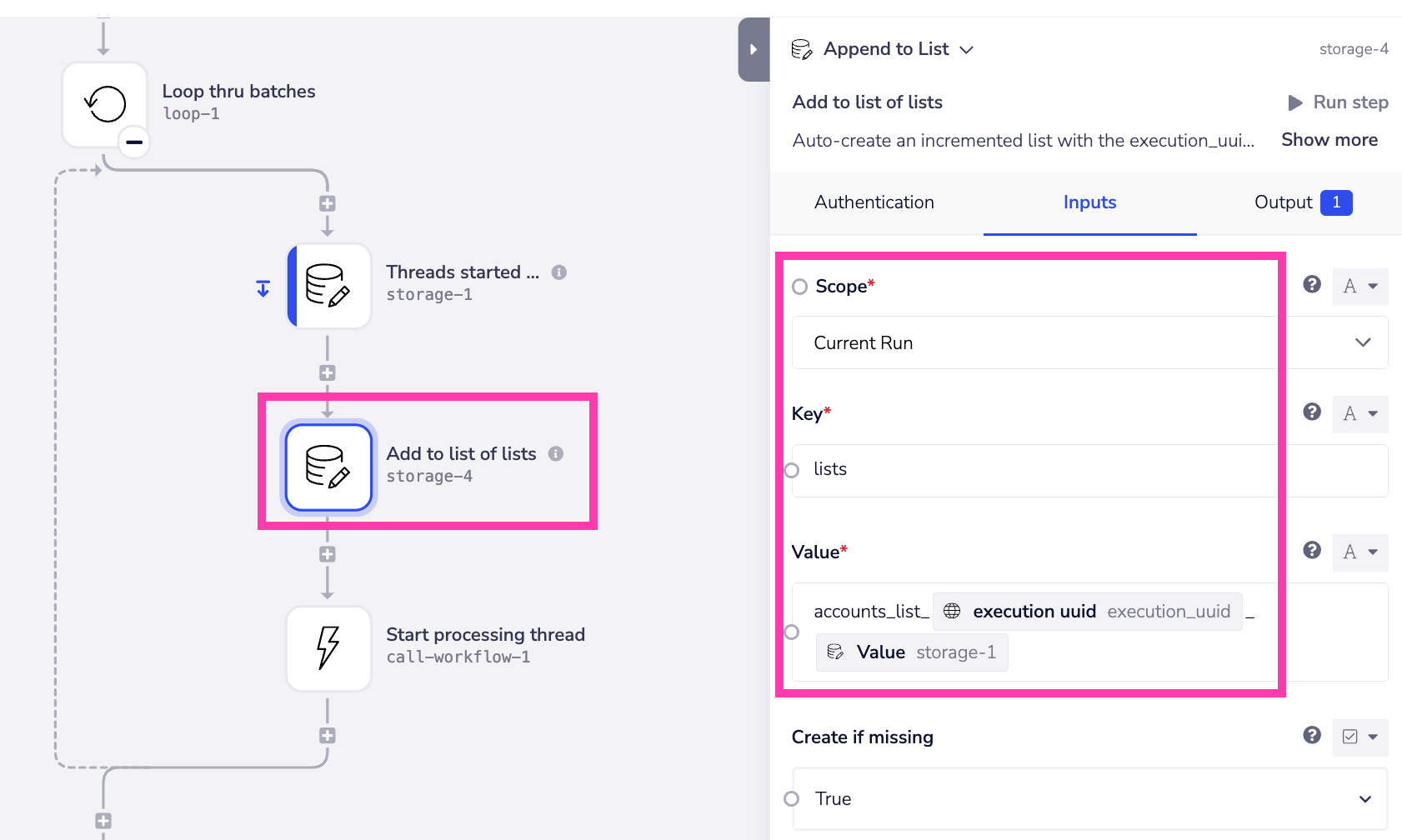
- Call the processing workflow, pass the data for the current batch as well as the name of the list to store the processed thread data in:
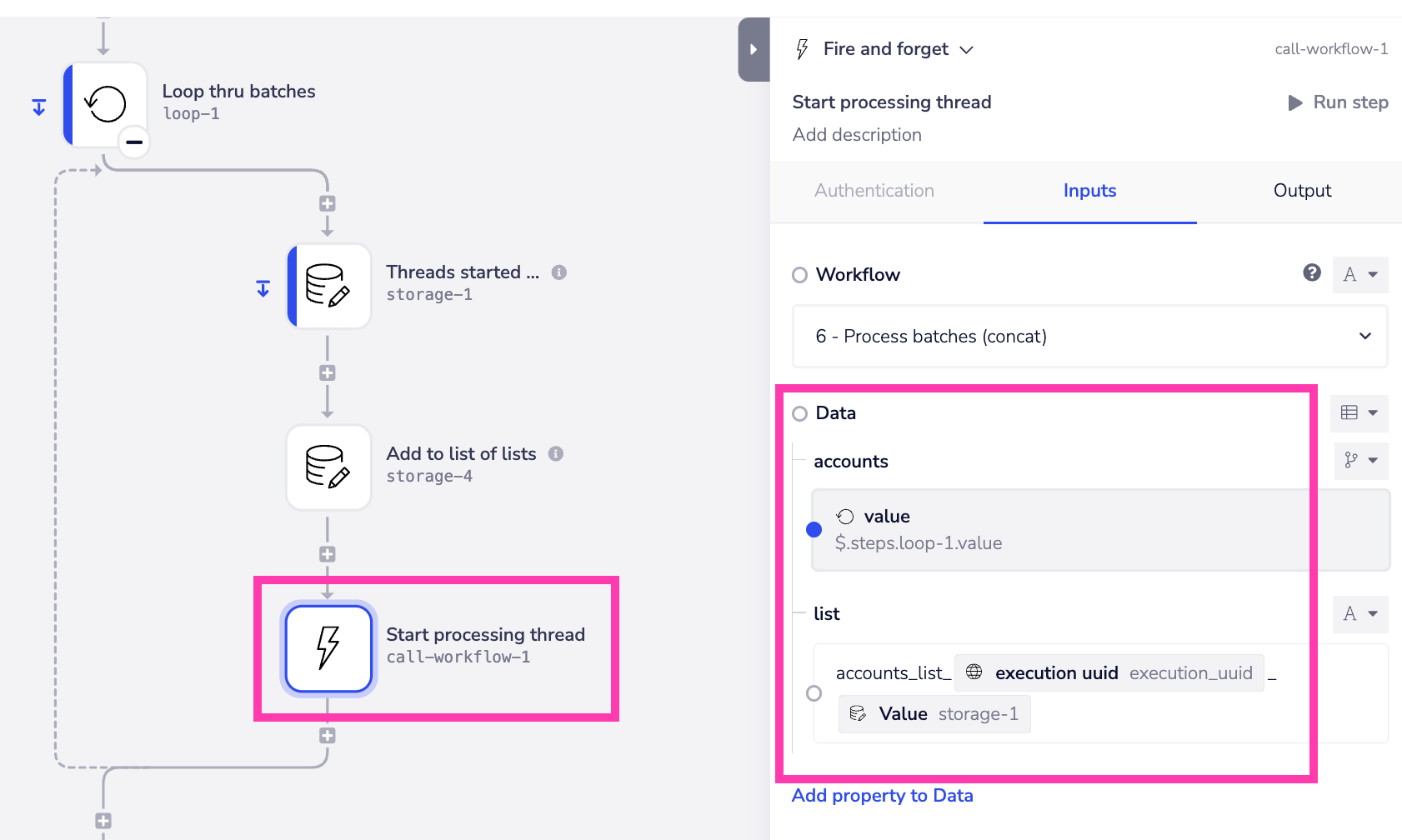
Section 3 - compare threads started and finished
This loop then gets the number of threads started (incremented in this workflow) and the threads finished (incremented when each thread completes in the processing workflow) and checks if they are equal. If so it will break the loop and continue to the next stage of the workflow. If not it will delay for 5 seconds before checking again. Note that, in a production setup you will also need to include a check for how long the workflow has been running, in case any threads have processing errors.
Section 4 - retrieve thread data and send to destination
The final stage is to retrieve the lists that were created by the processing threads. Using the record of lists created in Section 2, we can loop through each list name and use the Data storage 'get value' operation to retrieve that thread's data. Each retrieved list can then be sent to the destination (or to a callable workflow for final processing) within the same run of the loop. Processing each thread's list as it is retrieved means there is no need to combine all of the data into a single list before sending.
The processing workflow
In the processing workflow we loop through each item in the batch and carry out the necessary processing / enrichment on each item
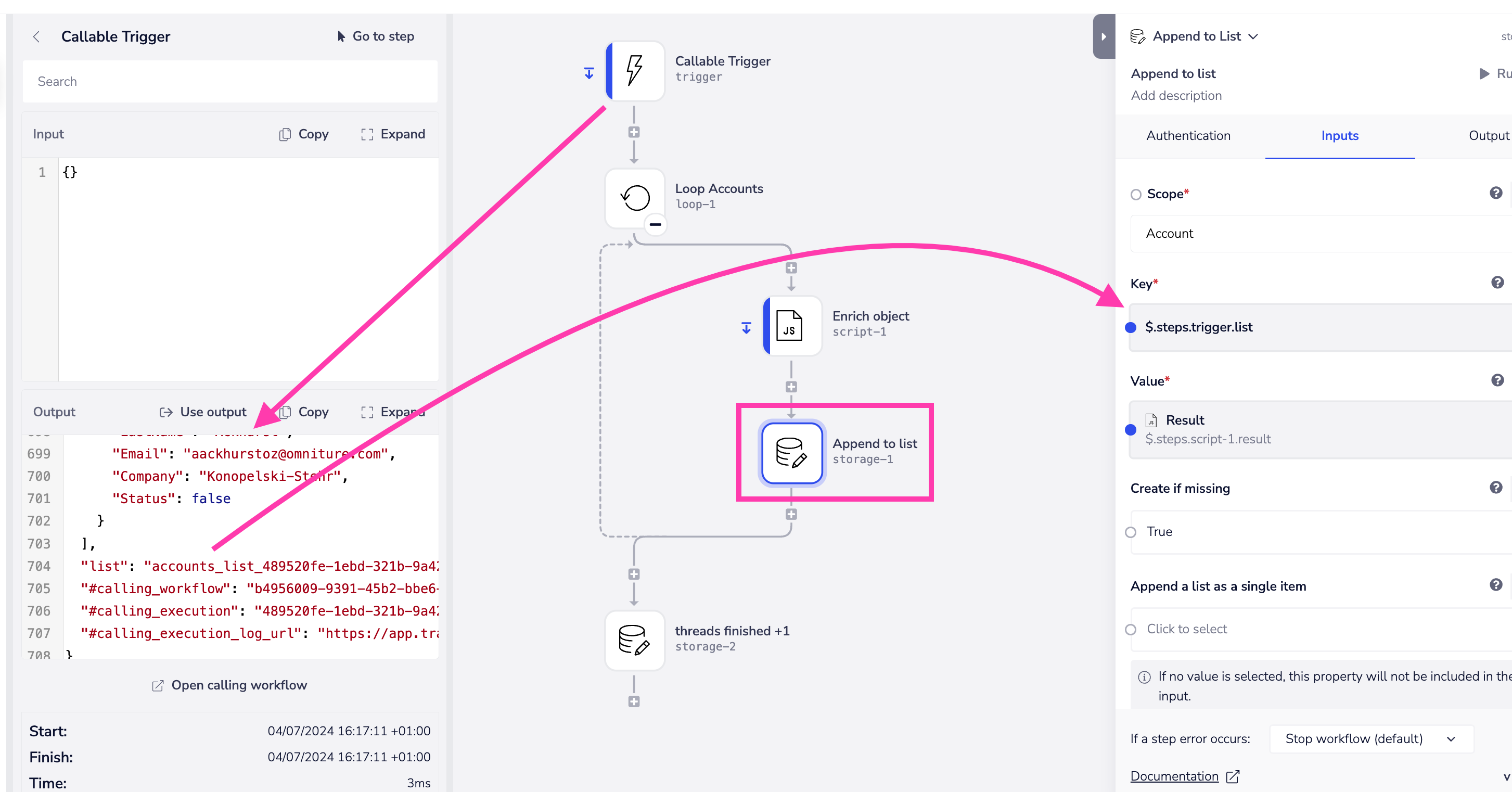 The steps involved are:
The steps involved are:
Important notes
Using a scheduled trigger
When polling with a scheduled trigger, it is very important to make sure that a run of the workflow is allowed to complete before any more runs are triggered. To do this first click on Advanced Properties and then tick the box as shown:
 Your schedule should also be set so that you allow plenty of time for runs to complete. In a case where 3 attempts at starting a run are made while one is still completing, these runs are missed. They are not added to a queue.
Note: any data processing steps (working with a messages list, uploading to airtable etc.) in this example are given for demonstration purposes only. The technique of threading is applicable in multiple scenarios and with many different connectors.
Your schedule should also be set so that you allow plenty of time for runs to complete. In a case where 3 attempts at starting a run are made while one is still completing, these runs are missed. They are not added to a queue.
Note: any data processing steps (working with a messages list, uploading to airtable etc.) in this example are given for demonstration purposes only. The technique of threading is applicable in multiple scenarios and with many different connectors.
Clearing account-level data
When testing, it is helpful to set a separate manually-triggered workflow which clears account level data as explained here. This means you can easily reset your data if your workflow errors out.