ETL (large scale)
ETL using the tray script connector
Note on scaling
When processing massive amounts of data - hundreds of thousands of rows at a time - it is recommended that you make use of a data warehousing operation which has specific capacity for high throughput, such as the Redshift COPY operation
Basic Extract, Transform and Load
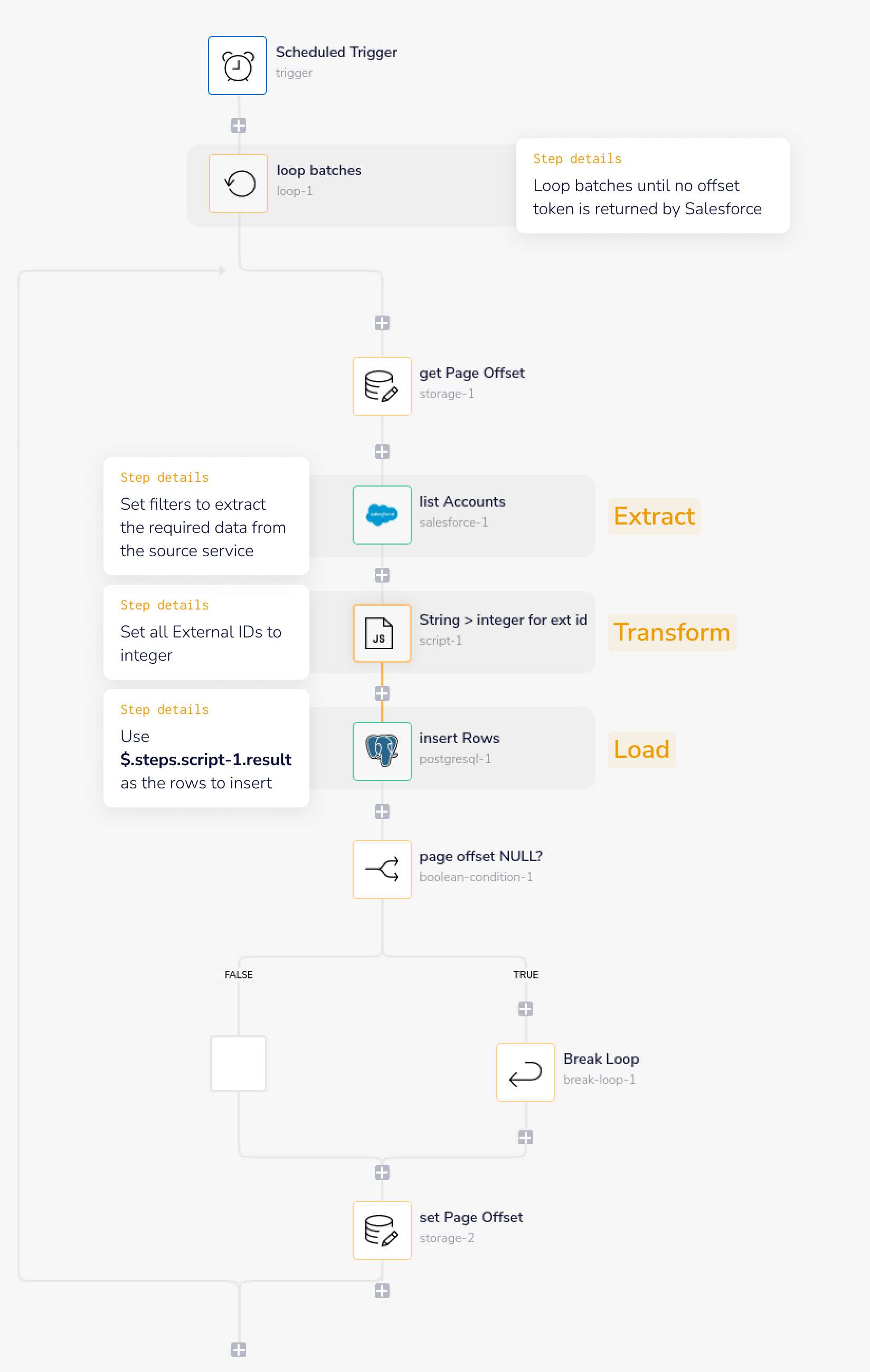
The following workflow illustrates a very simple example of extracting accounts from Salesforce and loading them into a Postgresql database.
You can click here to download and import your own instance of this workflow for testing and complete examination This kind of setup would be appropriate for dealing with fairly large amounts of data.
Note also that this setup assumes that you have already created the appropriate schema and tables in your database (please see below note on dynamically creating your tables based on the data that is being returned by the source service):
Scheduled trigger note
When using a Scheduled Trigger to run your ETL periodically, you will very likely need to implement the last runtime method
This has been left of the above workflow for the purposes of simplicity
The basic stages of this are:
1 - Extract the data from the source service (Salesforce accounts in this case) using the Loop connector to paginate through the results. This will come to an end when Salesforce no longer returns an offset token, indicating there are no more records to be found
2 - Carry out any necessary transformations on each batch of data being returned. This can be done to e.g. meet the requirements of your destination database. In this example we are transforming the External_ID__c field from string to integer:
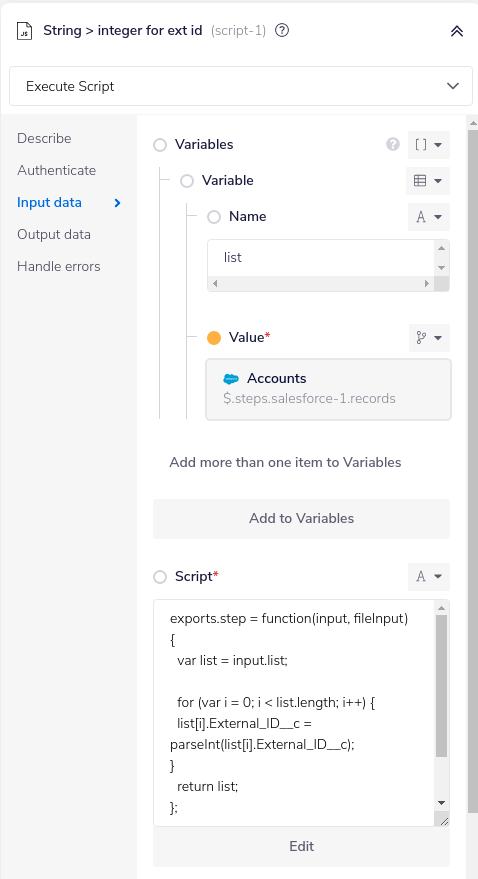 This uses a simple script to set all
This uses a simple script to set all External_ID__c values to integer:
exports.step = function(input, fileInput) {
var list = input.list;
for (var i = 0; i < list.length; i++) {
list[i].External_ID__c = parseInt(list[i].External_ID__c);
}
return list;
};
3 - Load the result into the destination database the resulting transformed data can then be loaded in one call as multiple rows to the destination database (Postgresql in this case):
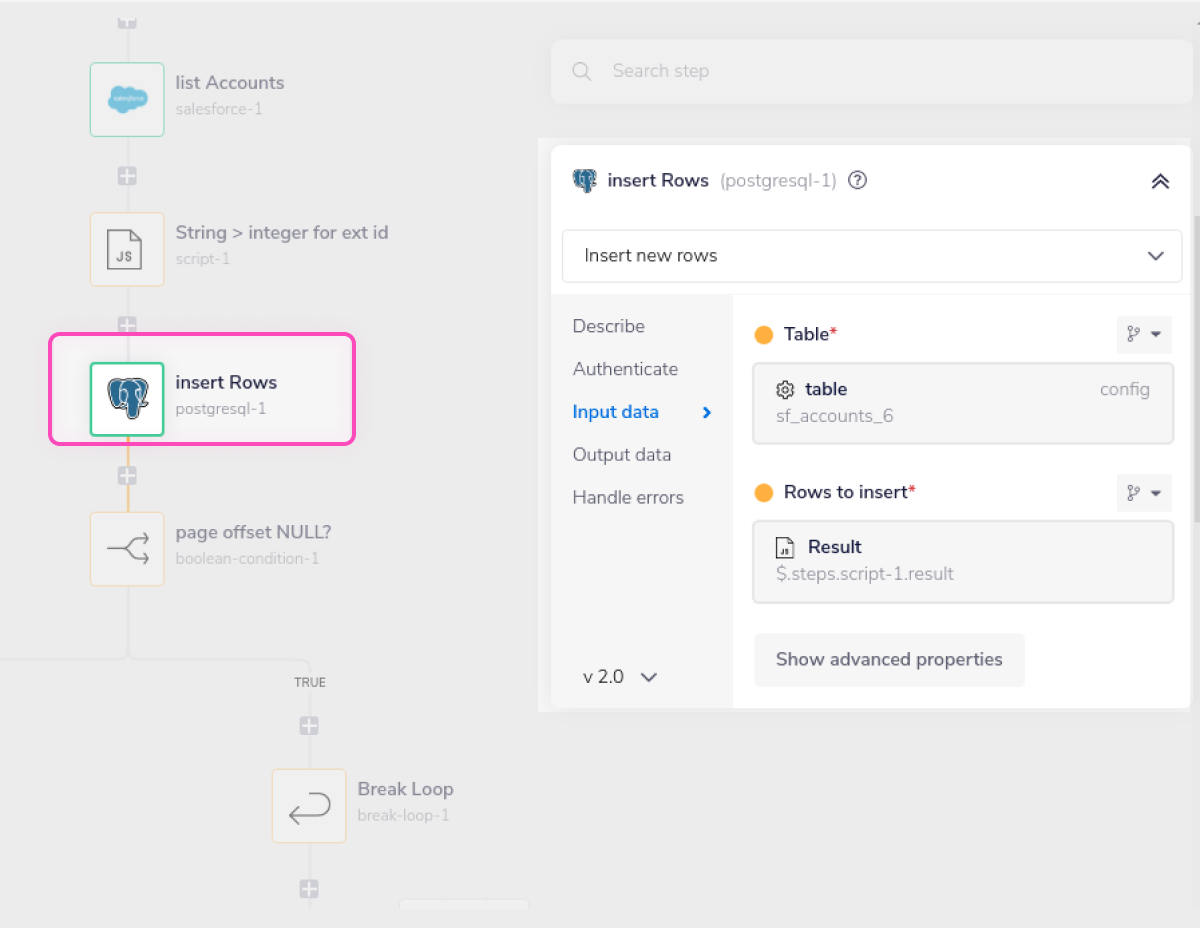 A key thing to note here is that all the accounts are loaded in one single call, rather than looping through the data and making e.g. 100 calls for each account.
A key thing to note here is that all the accounts are loaded in one single call, rather than looping through the data and making e.g. 100 calls for each account.
Managing data
Please see our Redshift documentation for guidance on how to deal with issues such as dynamic payloads. As mentioned in the note on scaling above, please also see our Redshift documentation for guidance on processing massive amounts of data via S3 and the COPY command
Other considerations
Failing workflows and error handling
Setting up error handling methods can help mitigate against workflows which might fail and hold up the completion of your threads.
The following example shows how we could get the details around an error associated with getting contact data and put them into a Google Sheets record of errors:
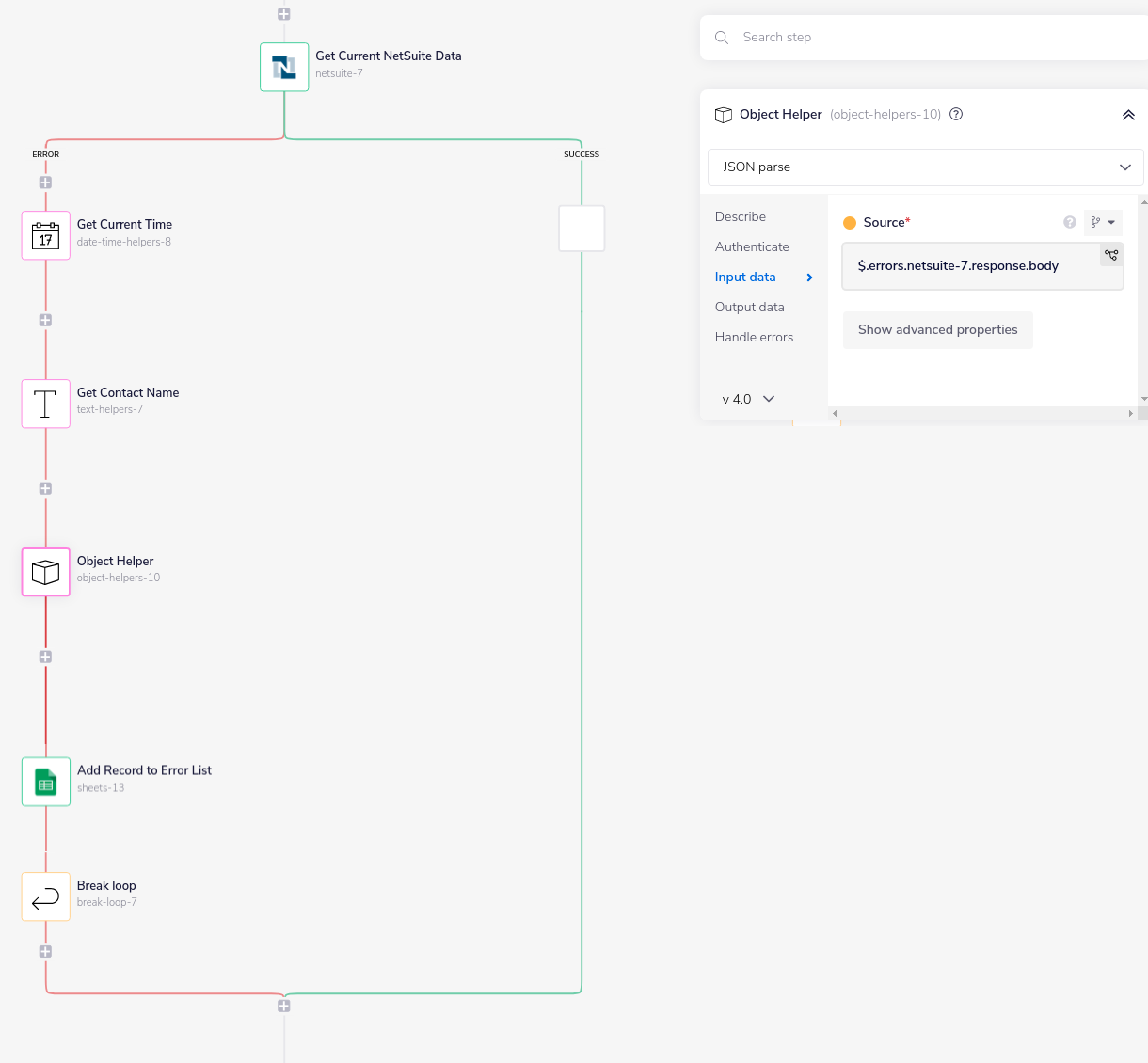 In this case we are extracting the timestamp, contact name and error message to add to each entry in Google Sheets, before breaking the loop to move on to the next contact.
In this case we are extracting the timestamp, contact name and error message to add to each entry in Google Sheets, before breaking the loop to move on to the next contact.
Dynamic schema creation
A requirement for your ETL project may be to dynamically generate the table schema in the destination database - perhaps because there is a vast number of potential fields, which would make the manual process extremely labor-intensive. That is to say that you will not be manually creating the table schema in your database before setting up the ETL system, and you want your Tray workflow to:
- Pull data from the source service
- Build the correct table schema (including the correct data types, allowed null values etc.) based on the data that has been returned
- Automatically create the table in the database and input the first batch of data
- Input all subsequent batches of data in accordance with the defined schema Subsequent to this you may also need to automatically respond to new fields added to the schema, or even such changes as fields being renamed. If dynamic schema creation is a requirement of your implementation please contact your Sales Engineer or Customer Success representative to discuss the exact requirements.
Problematic input schema
Some Data Warehouses, such as Google Big Query, may have input schema which is difficult to satisfy. In the case of Big Query, the following 'flat' input data:
"value": [
\{
"Email": "muhammad@tray.io",
"IsActive": true,
"Title": "Sales Engineer",
"Id": "0054xxxxxxxxWauSQAS",
"Name": "Muhammad Naqvi"
\}
]
Would need converted to the following:
"value": [
"row": {
"data": \{
"Email": "muhammad@tray.io",
"IsActive": true,
"Title": "Sales Engineer",
"Id": "0054xxxxxxxxxWauSQAS",
"Name": "Muhammad Naqvi"
\}
}
]
If you are having difficulties satisfying the schema requirements, please contact your Sales Engineer or Customer Succcess Representative.