

LLMs are everywhere in the enterprise. Some arrive embedded in SaaS. Others come through APIs that individual teams test on the side. A few run privately in isolated environments. Getting access is the easy part. The hard part is choosing the right models, connecting them to the right systems, and operating them with the right controls and guardrails.
This guide explains what LLM applications in the enterprise really look like, how to compare closed, open, and private options, and how to integrate LLMs so they deliver results without creating risk or runaway cost. If you’re responsible for scaling AI across a complex stack, this will help you cut through the noise.
What “LLM” means in the enterprise
When someone says “we need an LLM,” they might be picturing very different things.
- Closed LLMs such as OpenAI’s GPT family, Anthropic’s Claude, and Google’s Gemini are delivered via API or SaaS. They offer fast access to advanced capabilities but come with lock-in considerations.
- Open LLMs such as the Llama family or Mistral can be self-hosted or consumed as a managed service through platforms like AWS Bedrock or Azure. They give you flexibility and control, but you take on more of the integration, orchestration, and lifecycle management.
- Private LLMs are typically fine-tuned or domain-adapted versions of open models, trained on your data in your environment. They increase control and compliance, along with cost, operational burden, and the need for ongoing evaluation.
The decision is rarely about accuracy alone. You are weighing data control, compliance needs, latency expectations, rate limits and quotas, ongoing cost, switching risk, and how much integration work your team can take on. The most effective programs start with business goals and constraints, then choose models that fit those realities.
Why LLMs are now viable for the enterprise
Here’s a question: why are LLMs actually deployable at scale today when they weren’t 18 months ago?
You can point to three shifts that changed the equation: falling inference costs for many tasks, a surge of tooling maturity around retrieval, safety, and observability, and broader deployment options across clouds and VPCs (Virtual Private Clouds).
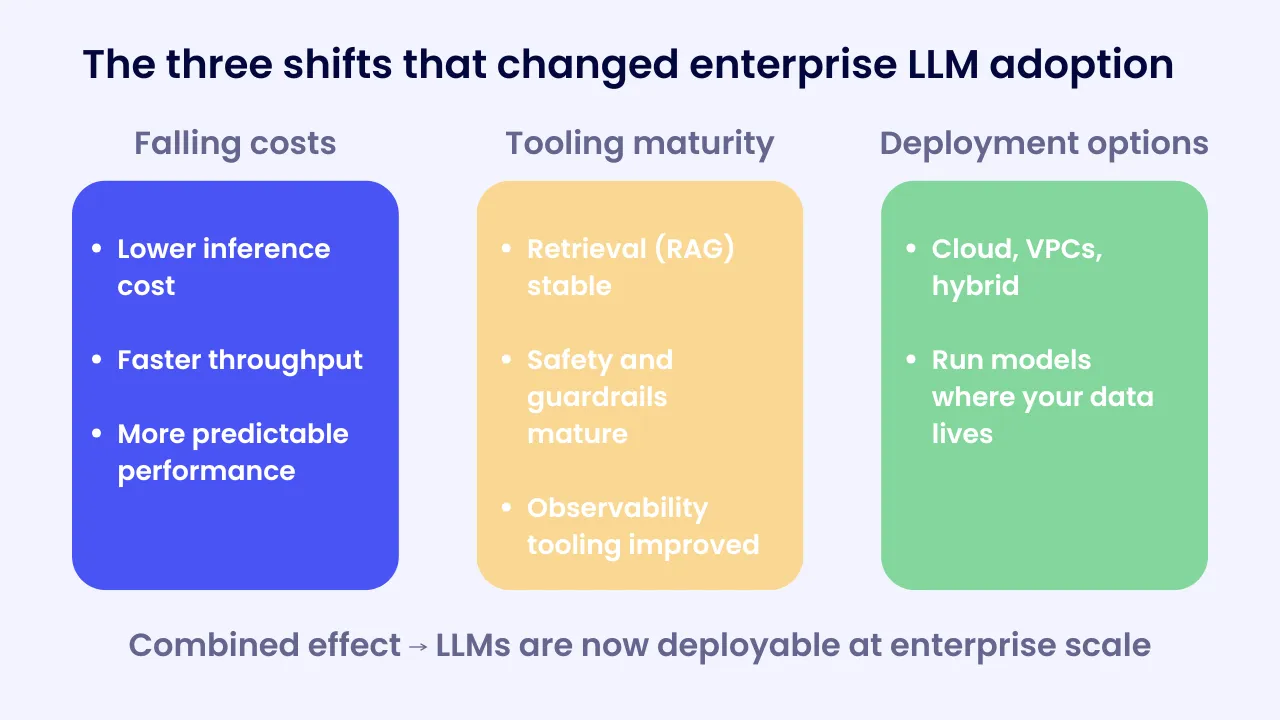
Put simply, it is now realistic to run LLMs where your data lives, supervise them with policy, and measure them against SLOs.
Designing around how LLMs actually behave
LLMs are not databases or rules engines. They are probabilistic reasoners that generate likely tokens given context. That shifts how you architect around them:
- Treat model outputs as proposals that must be grounded, validated, and sometimes approved.
- Keep truth in systems of record. Bring that truth to the model via retrieval.
- Design for guardrails: schema checks, policy checks, and clear fallbacks.
Where LLMs fit in enterprise use cases
LLMs create the most value when language and knowledge lead to a tangible action in your systems. In IT service management, they condense long threads, classify tickets, and route issues using context from identity and configuration data. In operations, they extract entities from documents, normalize records, and make routing decisions that move work forward. In HR, they answer policy questions, draft communications, and act only when permissions allow it. In analytics, they turn raw measurements into concise narratives that explain what changed and why.
All of these examples share the same foundation: reliable access to company data, strong guardrails, and the ability to take the next step in the tools your teams already use. Without those pieces, pilots stall.

Our survey of more than 1,000 enterprise leaders illustrates how teams are deploying LLMs and AI agents today:
- 61 percent cited IT service management, where ticket classification, triage, and resolution are well-bounded starting points.40 percent pointed to data workflows such as processing and analytics, where cleaning, categorization, and reporting consume large amounts of manual effort.
- 36 percent are automating customer service tasks beyond simple FAQs to improve response quality.
- 24 percent are using LLMs in HR automation for policy questions, provisioning, and employee support.
If you look closely at these use cases, you’ll see a common thread. LLM-powered systems only create value when they are connected to systems of record.
Think of LLMs like new appliances. The magic only happens once they’re connected to power and plumbing. In the enterprise, those “pipes” are identity, data, and operational tools. Integration is the challenge to solve.
Integration patterns that actually work
If the value shows up only when LLMs are connected into systems of record, start by getting the integration pattern right. Then choose models that fit that pattern.
Retrieval-augmented generation (RAG)
Bring accurate data to the model. Ingest the right documents, chunk them well, embed with rich metadata, and apply access rules. At query time, filter by metadata such as date ranges, departments, or document types. Retrieve and re-rank passages, then generate an answer with citations.
Enterprise details matter. Enforce ACLs when queries run. Scrub PII on ingest. Set freshness and re-indexing policies so answers reflect what’s true today. Poor chunking and missing metadata remain the fastest ways to degrade answer quality.
Tool use and function calling
When the model needs to take an action, keep it structured. The model selects a function, passes well-typed parameters, observes the result, and continues. Reliability comes from strict schemas, sensible timeouts and retries, idempotency, and least-privilege scopes for every tool.
Validate JSON when downstream systems require it. Log violations with enough context that someone can fix the root cause (and not guess at it).
Common failure modes to watch:
- The model selects the wrong function.
- Parameters are malformed even when a schema exists.
- A function returns success but makes the wrong business decision because the prompt lacked clear guardrails.
Real time and batch
Not everything needs to happen live. Use events for triage and routing where speed is visible to the user. Use schedules for background work such as summaries, classifications, and rollups so analytics and operations stay current without burning budget.
How to evaluate models without getting lost
Once your integration approach is defined, test models against reality. Treat model selection like any other platform decision that touches identity, data, and core systems.
Start with security and compliance
Confirm how data is handled, where it lives, how long it’s retained, and how regional routing works. Check certifications. Review governance features like output constraints, content filtering, redaction, and protections against prompt injection.
Measure quality on your content
Use your documents, your edge cases, and your safety stress prompts. Track groundedness and error patterns so comparisons are fair.
Then evaluate operational fit:
- Latency at realistic input sizes
- Structured-output reliability when downstream systems expect JSON
- Function-calling predictability when the model must use tools
- Rate-limit behavior under load
Confirm the production basics
You need version pinning, predictable deprecation windows, exportable observability, and clear cost controls. If those aren’t in place, the model won’t survive contact with production.
A simple lens keeps teams aligned:
- Will this meet our security and compliance bar?
- Will this perform on our data at our scale?
- Can we observe, control, and change it without breaking production?
Managing hallucination without hand-waving
Hallucination happens because models generate plausible text, not truth. The answer isn’t hand-waving. The answer is architecture.
Start by grounding responses in your own data. RAG with citations should be the default, and every answer should point back to what the model retrieved. When outputs need to feed downstream systems, enforce structure. Reject anything that doesn’t validate.
Control the model’s authority level. High-stakes actions still need human review. Narrow prompts help reduce ambiguity, and limiting which tools the model can call keeps it inside the right boundaries.
Hallucination will never disappear entirely. The goal is to make it detectable, low-impact, and easy to correct.
Data readiness comes first
LLM programs only move as fast as the data beneath them. If the foundation is weak, everything built on top of it slows down or breaks.
Start with accessibility. You need the right connectors, consistent formats, and parsers that can handle long-tail documents. Then ensure access is governed properly: row-level and document-level controls tied to identity, without side doors.
Freshness matters just as much. Knowledge bases and indices should be updated on a predictable schedule, with stale content quarantined so it doesn’t pollute answers.
If the data landscape is fragmented or out of date, fix that before you scale to more users or more use cases.
Measuring quality the same way every time
“Measure quality on your content” needs a method. Use a small, repeatable evaluation set per use case with clear metrics:
- Accuracy/groundedness: is the claim supported by the retrieved sources?
- Relevance/completeness: did it answer the question and include key details?
- Consistency: does the model answer the same way across similar inputs?
- Safety: refuses unsafe requests and avoids leaking PII.
Automate evals where possible. Many teams use LLM-as-a-judge patterns with spot checks by humans, plus targeted synthetic tests for edge cases. Track scores over time so regressions do not sneak in during prompt or model updates.
A model portfolio beats a single bet
No single model will serve every workload. A specialized extractor might be perfect for legal documents. A fast, high-quality API might be the right fit for customer chat. A fine-tuned open model might classify internal records at scale for a fraction of the cost.
Route by workload and contract, not by brand. The teams that win are the ones that treat models like components, not commitments.
A quick way to compare options
Here is a concise view of the main LLM choices and what to watch:
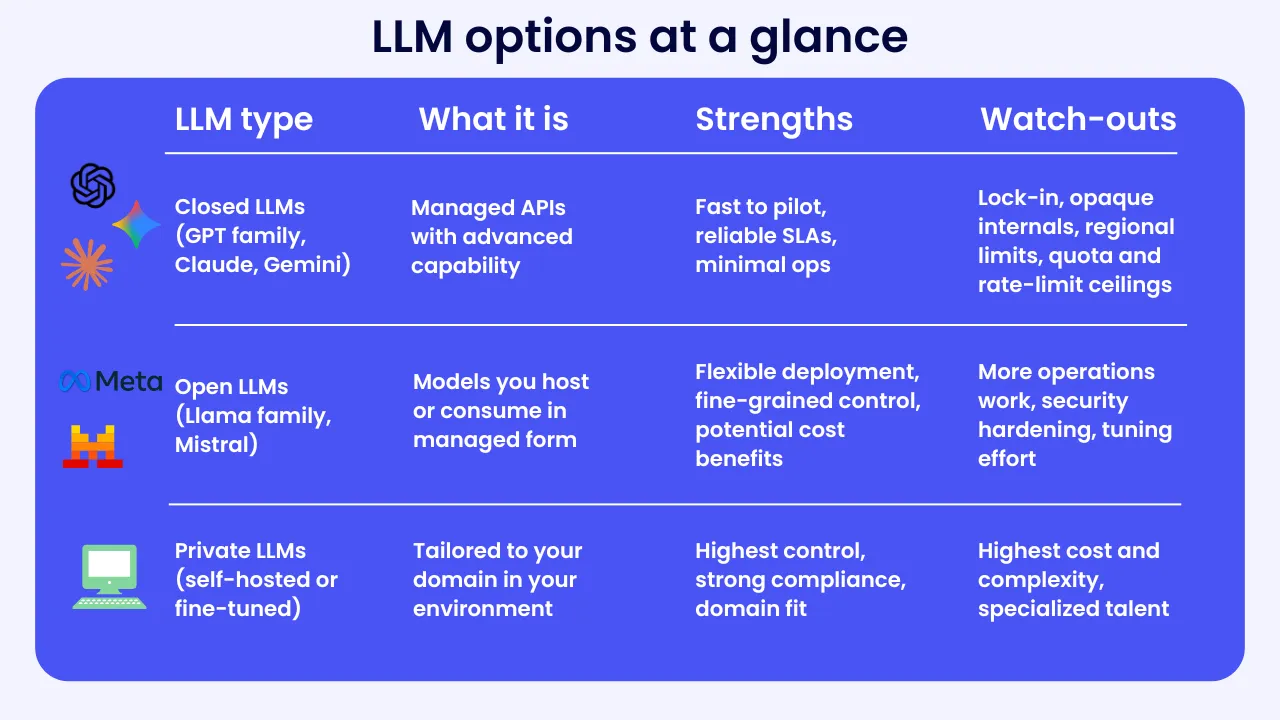
Enterprises rarely standardize on one type. Instead, they experiment across categories such as using a closed model for one workflow, a fine-tuned model for another. Without orchestration, this multiplies complexity.
Why orchestration matters
Tray.ai co-founder and CEO Rich Waldron calls this the “AI referee” problem: enterprises are stuck managing conflicting outputs from different models instead of leading AI strategy.
An LLM answering support tickets in Zendesk may contradict a model classifying incidents in ServiceNow. A finance LLM may approve spend that another model rejects. Without orchestration, IT ends up cleaning up after siloed AI instead of scaling it.
Orchestration is the difference between fragmented experiments and a sustainable LLM strategy.
Building an enterprise LLM strategy
Moving from prototype to production means thinking past individual models. Most sustainable programs follow the same progression.
Inventory what’s already deployed. Most enterprises already have LLMs embedded in tools. They’re just not connected.
Governance establishes access controls, compliance rules, and monitoring before conflicts show up.
Integration connects LLMs to the systems and data that give them context.
Orchestration unifies models, workflows, and policy so teams can scale without rebuilding foundations.
Reliability, performance, and cost you can live with
LLM workloads follow the same laws as any other production service. Set latency targets and use streaming when perceived speed matters. Track groundedness, citation validity, structured-output success, and task completion so changes are driven by data, not gut feel.
Costs stay predictable when prompts are tight, context windows are trimmed to what’s necessary, and repeated results are cached. Batch work that can wait. Avoid calling expensive tools for identical inputs. And apply the usual resilience patterns like timeouts, retries with backoff, and circuit breakers, so one flaky dependency can’t take down a workflow.
Re-evaluate everything when providers update models or when your own index drifts out of date.
Build or adopt: where to spend your time
You can assemble your own wrappers, retrieval, tools, and policy checks. That path gives you fine control, but it also creates a maintenance surface you’ll carry for years.
Or you can adopt an LLM-agnostic orchestration platform with deep connectors, role-based access, policy enforcement, observability, and model routing. That path gets you to value faster and lets your team focus on data quality, safety rules, and rollout.
Pick based on speed, risk, and scale. If many teams will build many use cases, recreating the plumbing for every project will slow you down.
Operating like a platform
Treat this as a platform capability. Assign ownership, SLAs, and a clear intake process. Review changes to prompts and tools the same way you review code. Define where humans approve, where they review, and where they simply monitor.
Start with one or two high-value use cases, template what works, and expand from there. Measure outcomes the business cares about: faster resolution, higher accuracy, less rework, and cost per task within target.
From experimentation to enterprise scale
Enterprises don’t succeed with LLMs by picking the “best” model. They succeed by building an architecture where models can be swapped, governed, and orchestrated across systems.
Whether closed, open, or private, the model matters. But the platform that connects and controls them matters more.
For a detailed comparison of different paths, from wrapper libraries to full unified platforms, see this overview of five approaches to building LLM-powered agents.